引入计算层 — 集算器
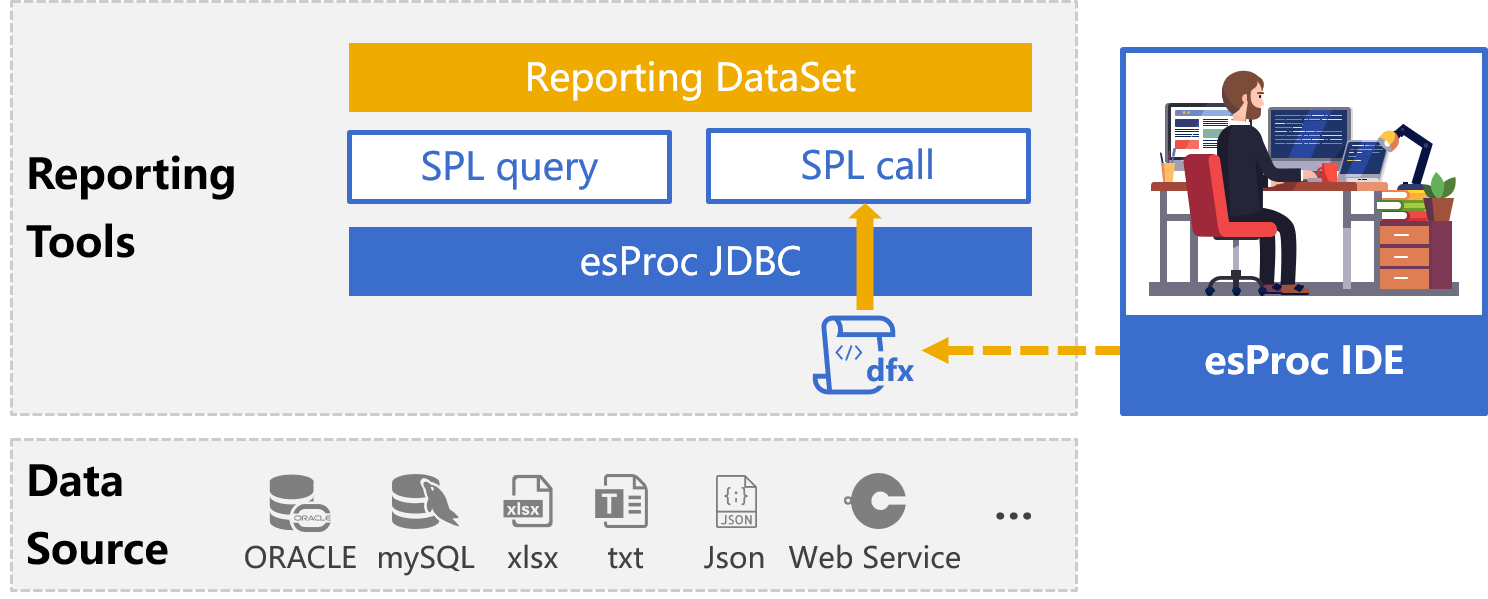
说明:SPL是esProc采用的脚本语言,dfx为脚本文件,相当于外置存储过程,报表通过JDBC接口传入SPL语句实现结构化计算或执行脚本。
说明:SPL是esProc采用的脚本语言,dfx为脚本文件,相当于外置存储过程,报表通过JDBC接口传入SPL语句实现结构化计算或执行脚本。
| 1 | select max(continuousDays)-1 |
| 2 | from (select count(*) continuousDays |
| 3 | from (select sum(changeSign) over(order by tradeDate) unRiseDays |
| 4 | from (select tradeDate, |
| 5 | case when closePrice>lag(closePrice) over(order by tradeDate) |
| 6 | then 0 else 1 end changeSign |
| 7 | from stock) ) |
| 8 | group by unRiseDays) |
思考:按照自然思维怎么做?!
| A | |
|---|---|
| 1 | =stock.sort(tradeDate) |
| 2 | =0 |
| 3 | =A1.max(A2=if(closePrice>closePrice[-1],A2+1,0)) |
语法体系更容易描述人的自然思维!
采用存储过程实现数据准备算法,会造成报表与数据库的耦合问题

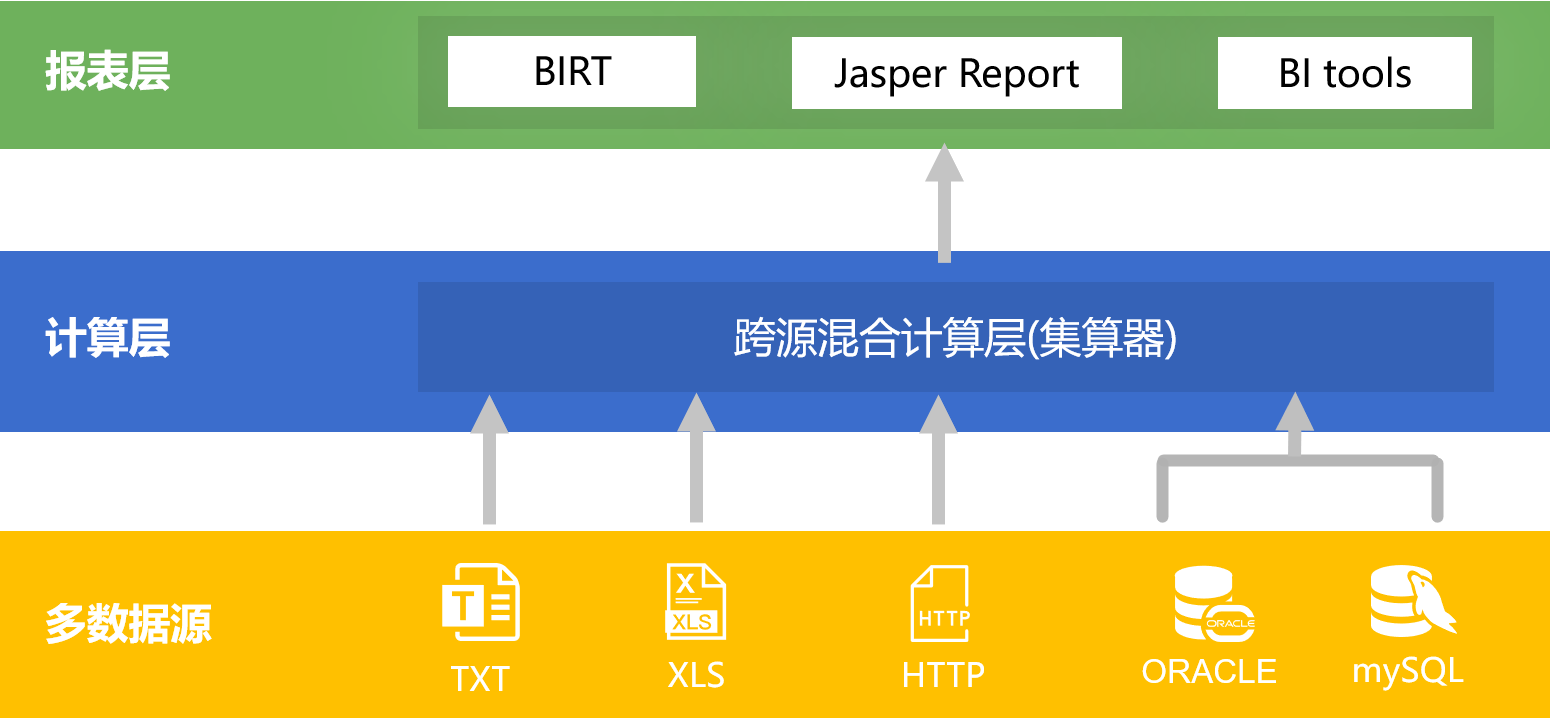
根据参数动态切换数据库
${pds}.query("select * from T where F=?",pF)
动态生成算法,动态拼接SQL
| A | B | |
|---|---|---|
| 1 | =sums.array().("sum("+~+") as "+~).string() | /把a,b变成sum(a) as a,sum(b) as b |
| 2 | =db.query("select G,"+A1+" from T group by G") |
结果集容量控制
| A | B | C | |
|---|---|---|---|
| 1 | =db.cursor("select * from T") | =A1.fetch(1000) | |
| 2 | if B1.fetch@0(1) | >B1.insert(0,"继续") | /未完成则插入标记 |
| 3 | >A1.close() | return B1 |
数据库JDBC性能较差,报表性能又严重依赖于取数环节;集算器可以采用多线程并行的方式同时建立多个数据库连接从数据库分段取数,可以获得数倍性能提升
| A | B | C | |
|---|---|---|---|
| 1 | fork 4 | =connect(db) | /分4线程,要分别建立连接 |
| 2 | =B1.query@x("select * from T where part=?",A1) | /分别取每一段 | |
| 3 | =A1.conj() | /合并结果 |
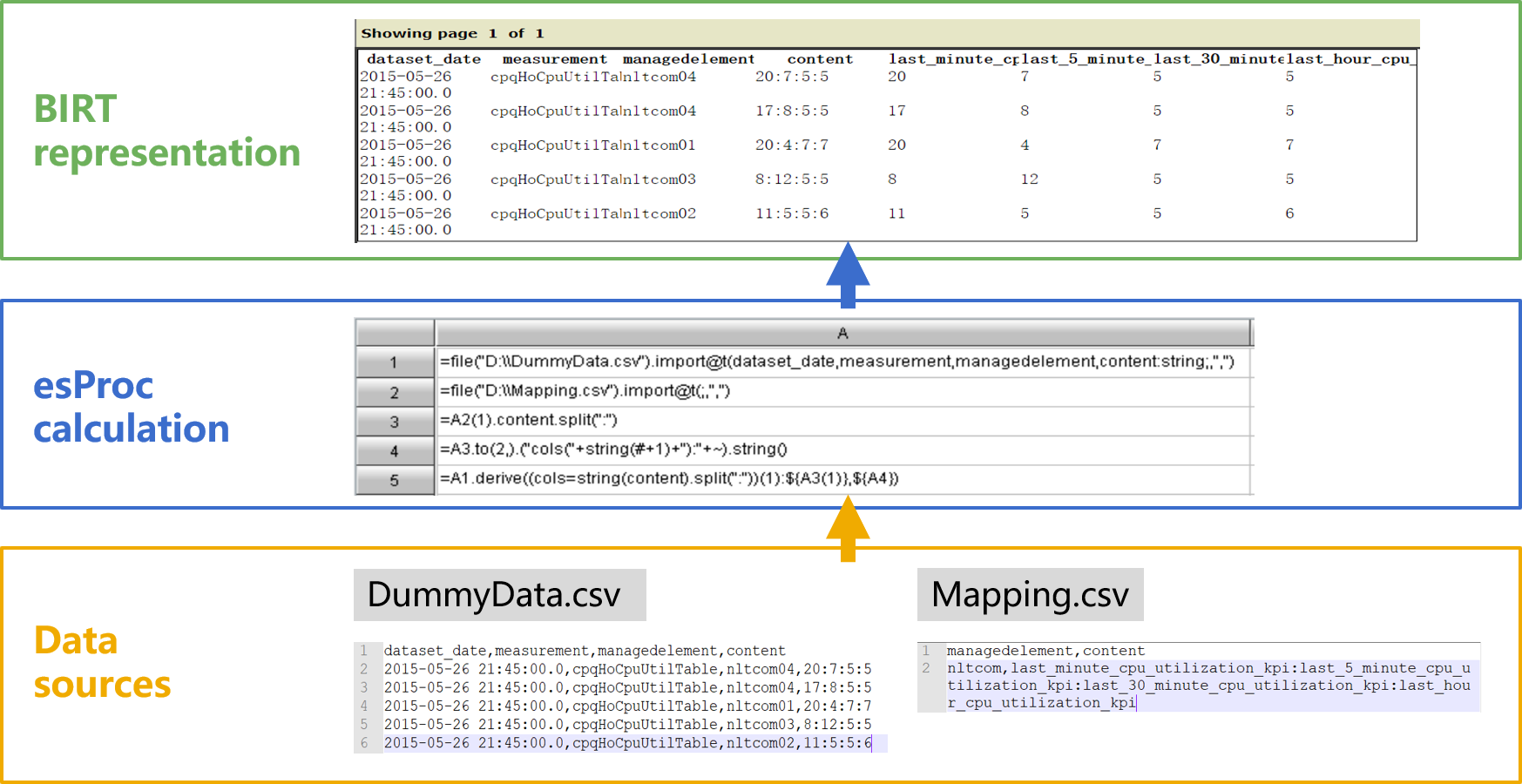
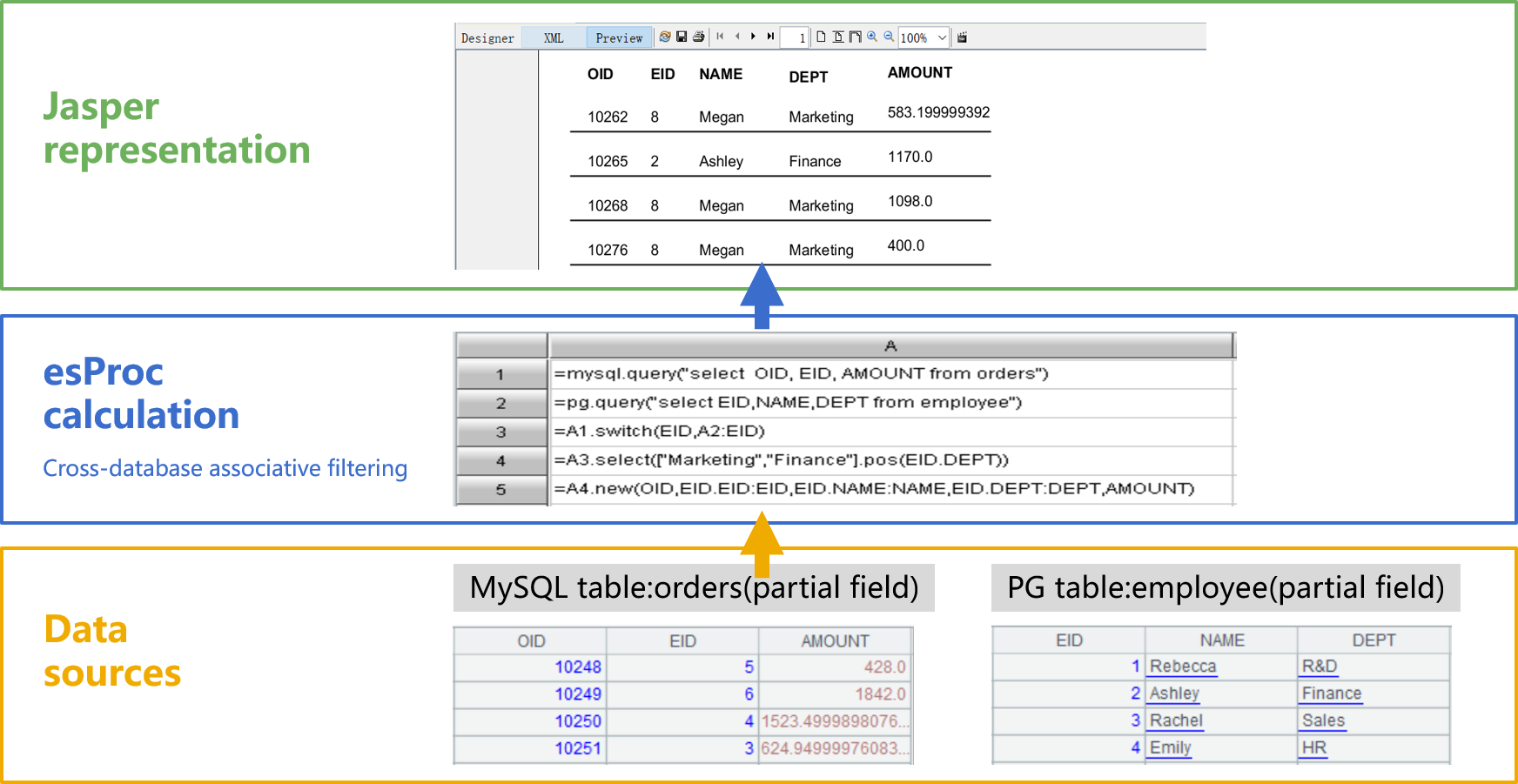
... Connection con = null; Class.forName("com.esproc.jdbc.InternalDriver"); con= DriverManager.getConnection("jdbc:esproc:local://"); // Calling stored procedures ,CountName is the file name of dfx st =(com. esproc.jdbc.InternalCStatement)con.prepareCall("call CountName()"); // Execute stored procedures st.execute(); //Get result set ResultSet rs = st.getResultSet(); ...
...
Connection con = null;
Class.forName("com.esproc.jdbc.InternalDriver");
con= DriverManager.getConnection("jdbc:esproc:local://");
// Calling stored procedures ,CountName is the file name of dfx
st =(com. esproc.jdbc.InternalCStatement)con.createStatement();
//Query files using SQL,get result set
ResultSet rs = st.executeQuery("$select name,count(*) from
/home/user/duty.txt group by name");
...