对Excel用户最友好超简洁强交互解决SQL难题数据分析编程语言
新颖的网格编程
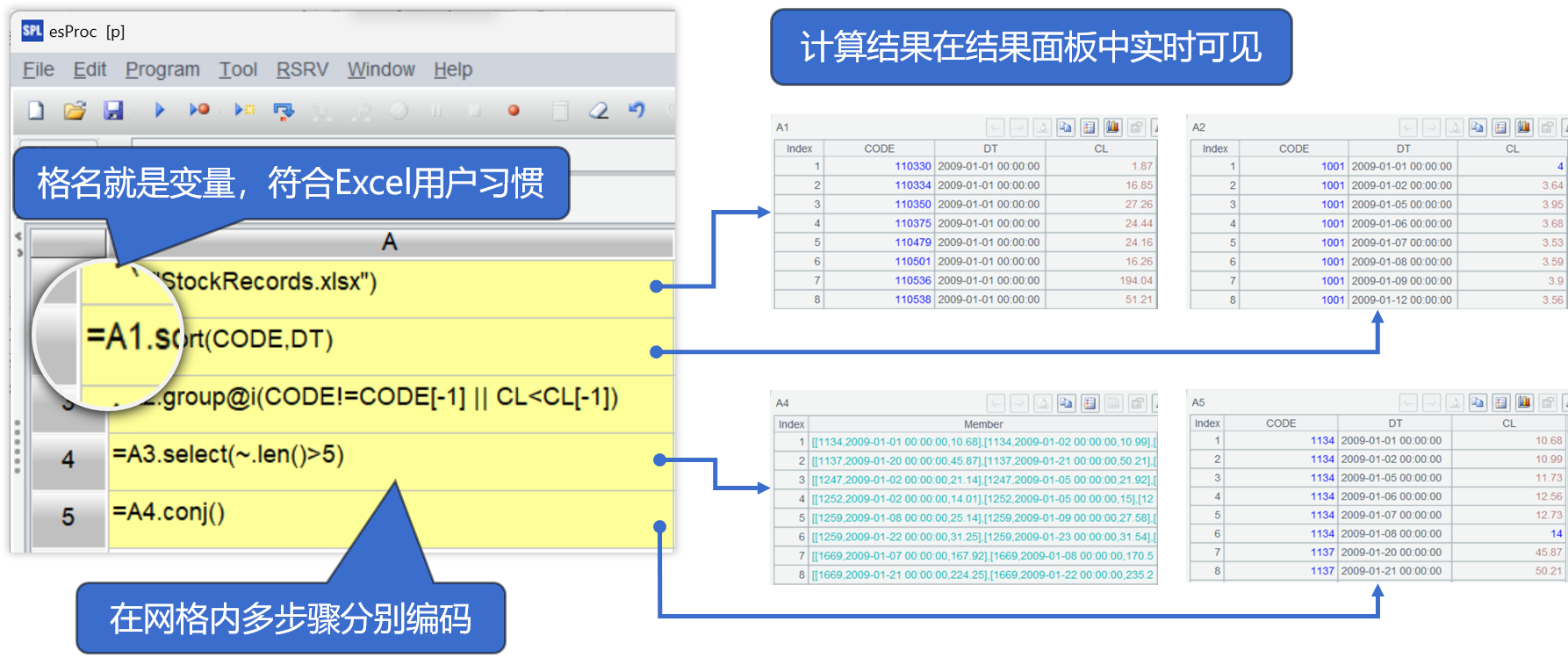
像Excel的网格编程
SELECT CODE, MAX(con_rise) AS longest_up_days
FROM (
SELECT CODE, COUNT(*) AS con_rise
FROM (
SELECT CODE, DT,
SUM(updown_flag) OVER (PARTITION BY CODE ORDER BY CODE, DT) AS no_up_days
FROM (
SELECT CODE, DT,
CASE WHEN CL > LAG(CL) OVER (PARTITION BY CODE ORDER BY CODE, DT) THEN 0
ELSE 1 END AS updown_flag
FROM stock
)
)
GROUP BY CODE, no_up_days
)
GROUP BY CODE
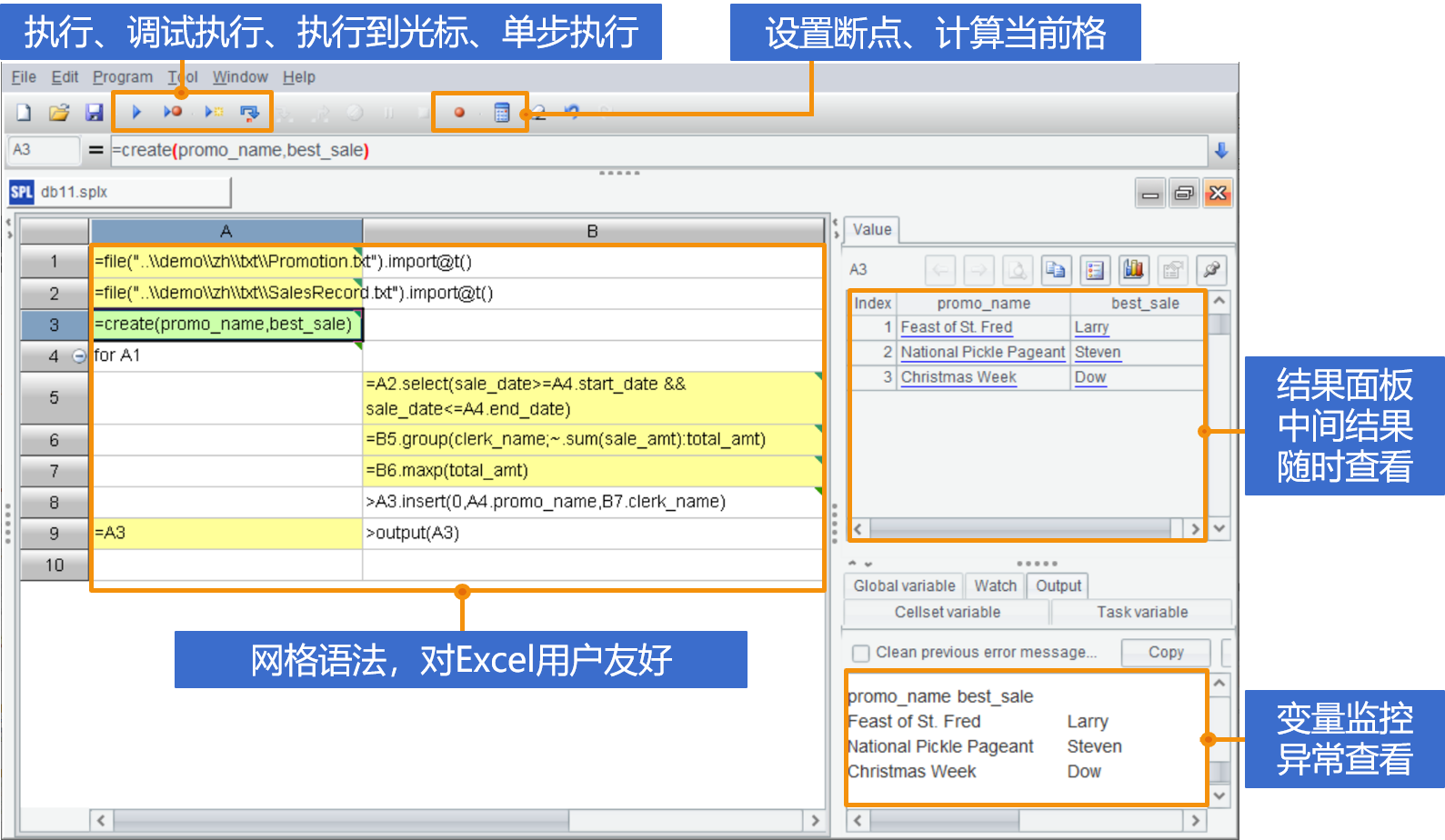
拆分SQL执行中间步骤
print大法输出中间结果
强交互性适应探索式分析

XLL插件辅助Excel
SPL代码直接写在Excel中:
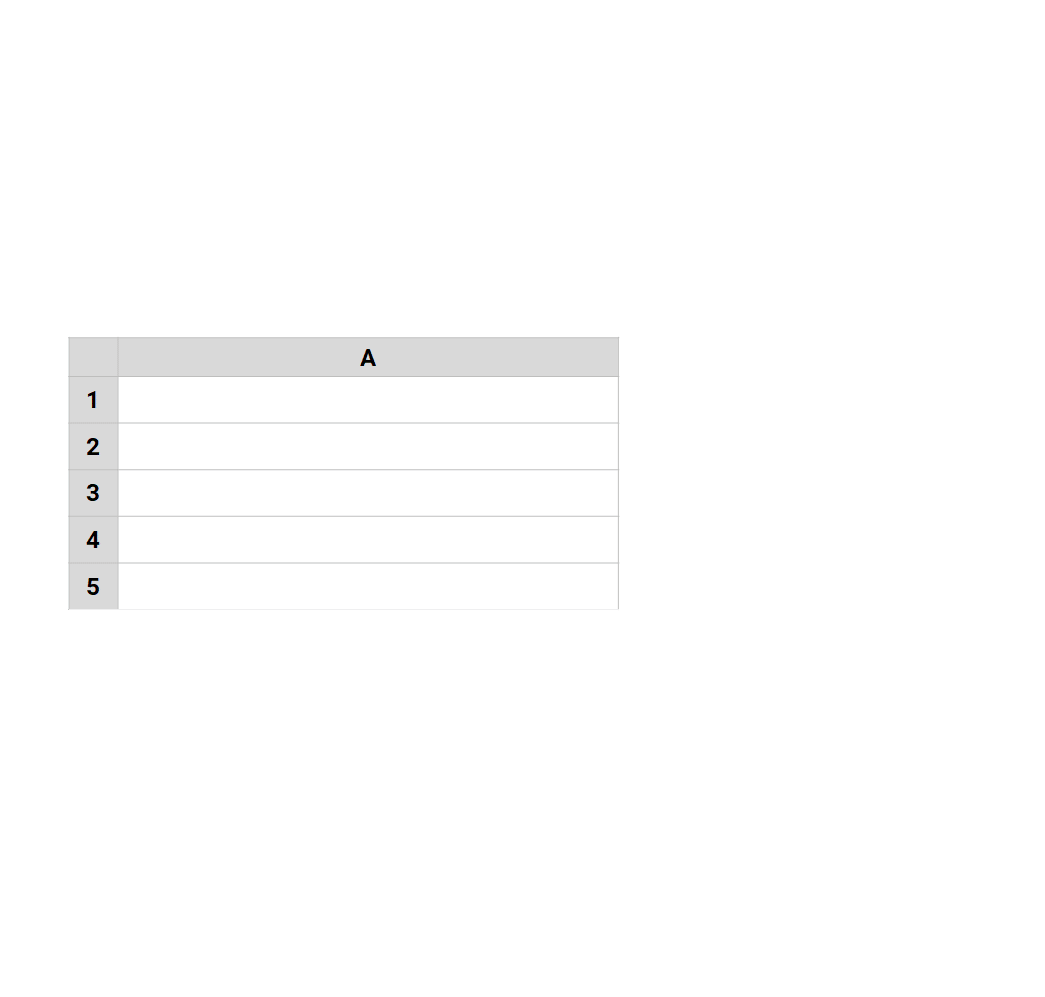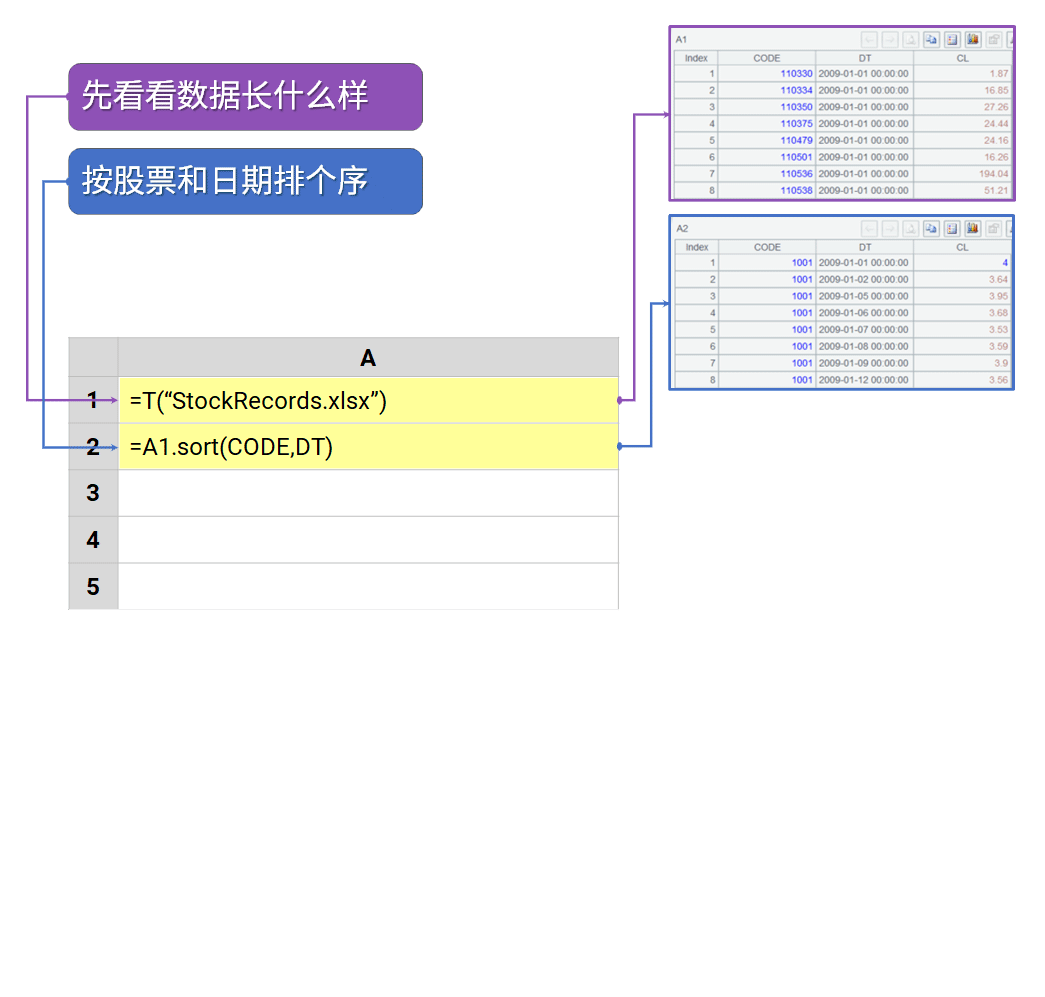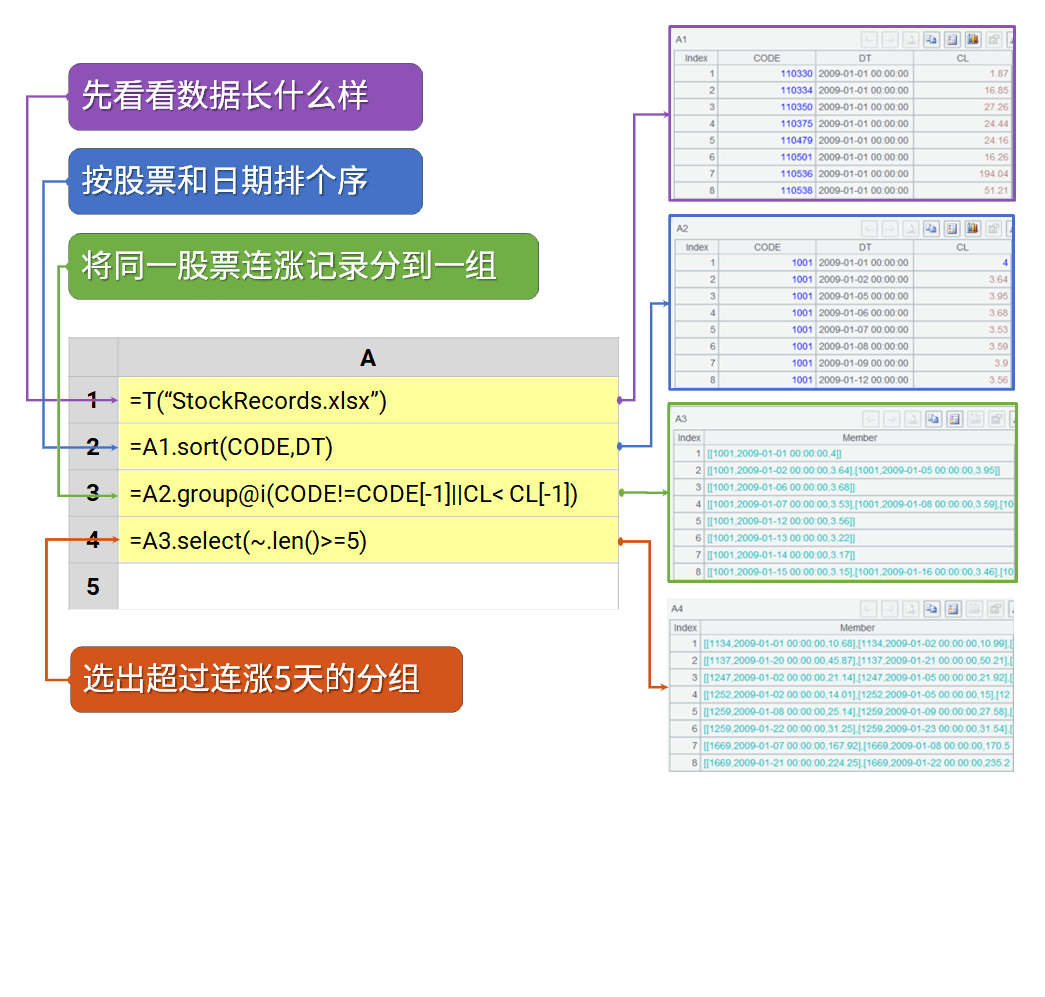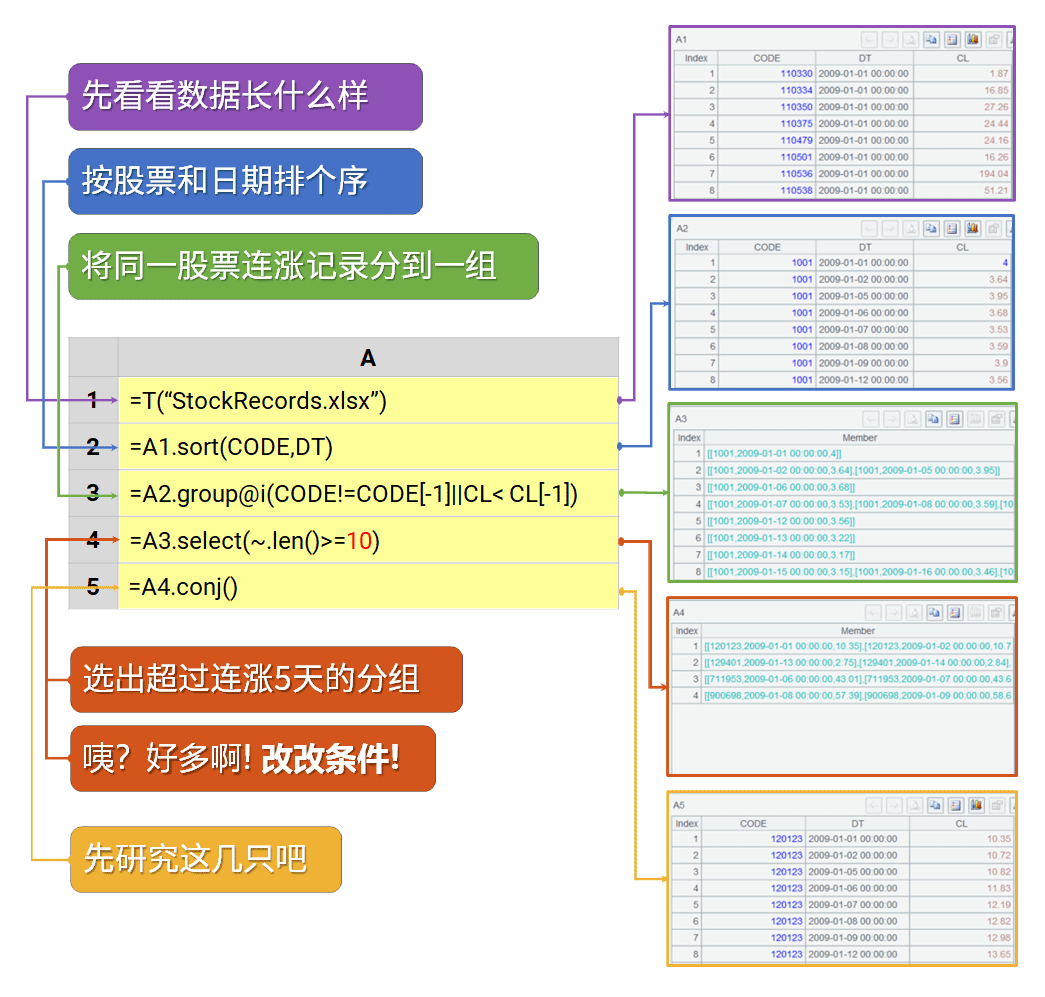
找出股票连涨超过5天的区间
=spl("=E(?1).sort(CODE,DT).group@i(CODE!=CODE[-1]||CL < CL[-1]).select(~.len()>=5).conj()",A1:D253)

简洁强大的代码
常规运算齐全简单

特有集合有序运算
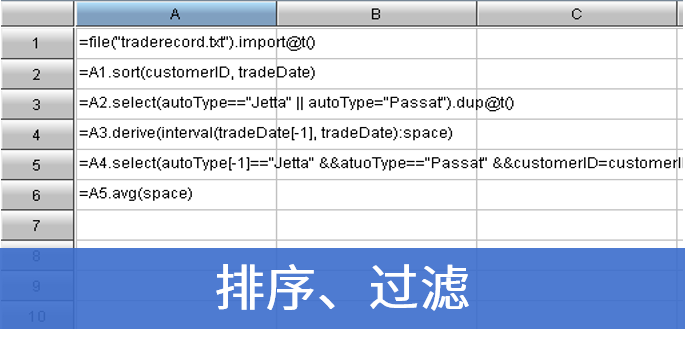
计算每支股票的最长连涨天数
特有集合有序运算
计算每支股票的最长连涨天数
SPL
| A | |
| 2 | StockRecords.xlsx |
| 3 | =T(A1).sort(DT) |
| 4 | =A2.group(CODE;~.group@i(CL < CL[-1]).max(~.len()):max_increase_days) |
特别擅长完成次序相关、移动窗口、跨行运算等复杂场景,比SQL、Python更简单
SQL
SELECT CODE, MAX(con_rise) AS longest_up_days
FROM (
SELECT CODE, COUNT(*) AS con_rise
FROM (
SELECT CODE, DT, SUM(updown_flag) OVER (PARTITION BY CODE ORDER BY CODE, DT) AS no_up_days
FROM (
SELECT CODE, DT,
CASE WHEN CL > LAG(CL) OVER (PARTITION BY CODE ORDER BY CODE, DT) THEN 0
ELSE 1 END AS updown_flag
FROM stock
)
)
GROUP BY CODE, no_up_days
)
GROUP BY CODE
Python
import pandas as pd
stock_file = "StockRecords.txt"
stock_info = pd.read_csv(stock_file,sep="\t")
stock_info.sort_values(by=['CODE','DT'],inplace=True)
stock_group = stock_info.groupby(by='CODE')
stock_info['label'] = stock_info.groupby('CODE')['CL'].diff().fillna(0).le(0).astype(int).cumsum()
max_increase_days = {}
for code, group in stock_info.groupby('CODE'):
max_increase_days[code] = group.groupby('label').size().max() – 1
max_rise_df = pd.DataFrame(list(max_increase_days.items()), columns=['CODE', 'max_increase_days'])
简易的大数据与并行支持
大数据
内存
| A | |
| 1 | StockRecords.txt |
| 2 | =file(A1).import@t().sort(CODE,DT) |
| 3 | =A2.group(CODE;~.group@i(CL < CL[-1]).max(~.len()):mi) |
外存
| A | |
| 1 | StockRecords.txt |
| 2 | =file(A1).cursor@t().sort(CODE,DT) |
| 3 | =A2.group(CODE;~.group@i(CL < CL[-1]).max(~.len()):mi) |
并行计算
串行
| A | |
| 1 | StockRecords.txt |
| 2 | =file(A1).cursor@t().sortx(CODE,DT) |
| 3 | =A2.group@i(CODE!=CODE[-1]||CL< CL[-1]) |
| 4 | =A3.select(~.len()>=5).conj() |
并行
| A | |
| 1 | StockRecords.txt |
| 2 | =file(A1).cursor@tm().sortx(CODE,DT) |
| 3 | =A2.group@i(CODE!=CODE[-1]||CL< CL[-1]) |
| 4 | =A3.select(~.len()>=5).conj() |
轻量又便携
