7.7.2分批处理大数据文本文件
当文件中的数据量比较大时,全部读入内存就有可能造成内存溢出,这种时候就需要读取文件中的部分数据。在使用import时,还可以使用分段参数,分段读取数据。如:
|
|
A |
|
1 |
=file("PersonnelInfo.txt") |
|
2 |
=A1.import@t(;100:500) |
|
3 |
=A1.import@t(;101:500) |
文本文件PersonnelInfo.txt中,存储了一批员工资料。A2和A3在使用import函数时,在分号后添加了分段参数,如100:500,此时A2读取数据时,将数据分为500份,读取其中的第100份,结果如下:
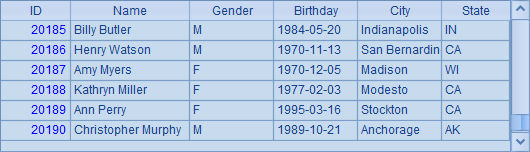
A3中继续读取第101份,结果如下:
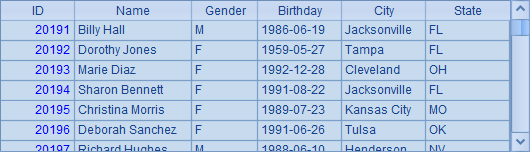
可以发现,在分块读取时,集算器也会调整位置使得读取时整条读入记录,同时保证读取时数据的连续性,避免出现重复或遗漏。
需要注意的是,在import函数中,用分段的方法来分多次从文件中读取数据时,由于每条记录占用的字节数不定,因此每次读到的数据条数也是有变化的。由于同样的原因,也是无法直接获取指定某行的数据的。如果想找到指定位置的某行记录,只有遍历读取它前面的所有数据,效率低下。如果需要精确访问记录,可以使用外存文件游标来处理,将在下一节内容中介绍。
将大数据文件分段,这样就可以把单文件的计算任务拆分为多个子任务执行。因此,分段读取数据对于集群计算很有意义,在8.3服务器 中,将讲解如何在集群计算中分批处理大数据文件。
在面对大数据的计算时,在输出数据到文本文件时,同样会受到内存的限制。由于数据无法一次读入到内存,也就不能简单export到某个文件。对于大数据的输出,同样可以分批处理,使用时需要在export函数中添加@a选项,每次输出时,都在已有的数据后面添加导出。如:
|
|
A |
B |
|
1 |
=file("PersonnelInfo.txt") |
=file("PersonnelInfo1.txt") |
|
2 |
for 500 |
=A1 .import@t(ID,Name,State;A2:500,) |
|
3 |
|
>B1.export@at(B2) |
在A2中执行循环,分500次读出PersonnelInfo.txt中的数据,并选择部分字段存储到新文件PersonnelInfo1.txt中。在存储时,添加了@at选项,输出列名,同时每次写数据时都用附加的方式。执行后,文件PersonnelInfo1.txt中数据如下:
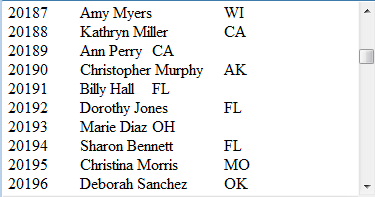
如果没有添加@a选项,在输出时则会把文件中原有数据清除。