7.3.1游标的分组聚合运算
最常见的分组聚合运算,就是计数与求和,除此以外,聚合运算还包括求最大值、最小值及前n个数据。对游标中的数据聚合运算,可以使用cs.groups() 函数,各类聚合运算对应的聚合函数分别为count/sum/max/min/top/avg/iterate如:
|
|
A |
|
1 |
=file("Order_Wines.txt") |
|
2 |
=file("Order_Electronics.txt") |
|
3 |
=file("Order_Foods.txt") |
|
4 |
=file("Order_Books.txt") |
|
5 |
=[A1:A4].(~.cursor@t()) |
|
6 |
=A5.mergex(Date) |
|
7 |
=A6.groups(Type;count(~):OrderCount,max(Amount):MaxAmount,sum(round(decimal(Amount),2)):Total) |
在A7中,分种类统计了各类商品的订单总数、最大交易金额及总金额。需要注意的是,在大数据计算中,双精度数据的精度往往不够,此时需要用decimal() 将数据转换为数值类型计算。在游标的分组聚合运算中,所有数据都会被遍历一次,遍历时,对每行记录执行它在相应分组的聚合计算,在一次遍历中可以同时计算多个聚合值,在遍历完成后游标会自动关闭。
A7中结果如下:

可以看出,在使用的测试文本数据中,每类商品的订单记录各有50,000条。各个文件中的数据,以及A6游标中的数据都是关于Date有序的,但是对Type并非有序,从例子中函数的使用可以知道,使用cs.groups() 函数分组汇总时,不需要游标中的数据有序。而在分组聚合后,结果会根据分组值排序。另外,由于cs.groups() 函数返回序表,因此,使用这个函数处理游标的分组聚合运算时,结果集必须是内存可以容纳的,而不适用于结果集本身是大数据的情况。
在聚合运算时,还可以统计最大/最小的n个数据,此时的聚合函数用top:
|
|
A |
|
1 |
=file("Order_Wines.txt") |
|
2 |
=file("Order_Electronics.txt") |
|
3 |
=file("Order_Foods.txt") |
|
4 |
=file("Order_Books.txt") |
|
5 |
=[A1:A4].(~.cursor@t()) |
|
6 |
=A5.mergex(Date) |
|
7 |
=A6.groups(Type;top(3,Amount):MinAmount,top(3,-Amount):MaxAmount) |
在A7中计算了每类商品订单中,总价最低的3笔订单金额和总价最高的3笔订单金额,注意其中计算最高3笔金额时,在聚合函数中添加负号,用top(3,-Amount)。结果如下:
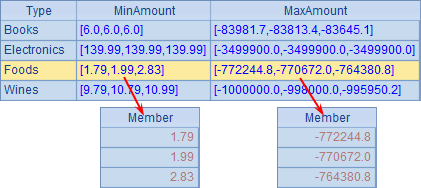
如果需要对所有记录做聚合运算,只需将在cs.groups函数中将分组表达式部分置空:
|
|
A |
|
1 |
=file("Order_Wines.txt") |
|
2 |
=file("Order_Electronics.txt") |
|
3 |
=file("Order_Foods.txt") |
|
4 |
=file("Order_Books.txt") |
|
5 |
=[A1:A4].(~.cursor@t()) |
|
6 |
=A5.mergex(Date) |
|
7 |
=A6.groups(;count(~):Count,sum(round(decimal(Amount),2)):TotalAmount) |
A7中结果如下:
![]()
由此可见,对所有记录的聚合运算,可以视为一种特殊的分组聚合。