5.4.2使用clear语句清除格值
在一段代码执行后,有可能有一批单元格中的格值都需要清除,而只保留最终结果。如下面的例子:
|
|
A |
B |
|
1 |
=file("Order_Appliances.txt").import@t() |
|
|
2 |
=file("Order_Foods.txt").import@t() |
=A1|A2 |
|
3 |
=B2.top(200,-Amount, ~).new(ID, PName,Type,Date,Amount) |
|
|
4 |
=A3.sort(PName) |
|
|
5 |
>A1=null |
>A2=null |
|
6 |
>B2=null |
>A3=null |
这里与前面的例子类似,A4中计算的目的是取得订单总额前200名的订单记录,并按商品名称排序。计算后,为了降低内存损耗,在A5,B5,A6和B6中将不再使用的格子中的格值清除。这样的写法显然显得有些繁琐,为此,在集算器中特别提供了clear命令:
|
|
A |
B |
|
1 |
=file("Order_Appliances.txt").import@t() |
|
|
2 |
=file("Order_Foods.txt").import@t() |
=A1|A2 |
|
3 |
=B2.top(200,-Amount, ~).new(ID, PName,Type,Date,Amount) |
|
|
4 |
=A3.sort(PName) |
|
|
5 |
clear A1,A2,B2,A3 |
|
网格的执行效果和上面是相同的。A5中的clear命令,可以一次清除多个单元格中的格值。另外,在clear命令中还可以指定单元格区域,如:
|
|
A |
B |
|
1 |
=file("Order_Appliances.txt").import@t() |
|
|
2 |
=file("Order_Foods.txt").import@t() |
=A1|A2 |
|
3 |
=B2.top(200,-Amount, ~).new(ID, PName,Type,Date,Amount) |
|
|
4 |
=A3.sort(PName) |
|
|
5 |
clear A1:B3 |
|
A5的clear命令中,A1:B3表示A1到B3格所在的矩形区域,即A1,B1,A2,B2,A3,B3所组成的区域,clear命令会清除所有这些单元格的格值。在clear命令中,单个单元格和单元格区域的写法可以同时使用。如A5中的clear命令也可以写为clear A1:B2,A3,效果是相同的。
再来看下面的网格:
|
|
A |
B |
|
1 |
[Order_Appliances.txt,Order_Foods.txt] |
=[0]*A1.len() |
|
2 |
for A1 |
=file(A2).import@t() |
|
3 |
|
=B2.top(100,-Amount,~) |
|
4 |
|
=B3.sort(PName) |
|
5 |
|
>B1(#A2)=B4 |
|
6 |
=B1.merge(PName) |
|
|
7 |
=A6.new(ID, PName,Type,Date,Amount) |
|
表中的计算和前面稍有不同。这个网格中的代码,根据A1中的文件名,读取出数据,并从每个表中获取订单总额前100名的记录,将其按商品名称排序后,结果作为1个成员存储在序列B1中。由于结果已各自按商品名称排序,因此可以在A6中将所有结果按商品名称归并。最终在A7中生成结果序表如下:
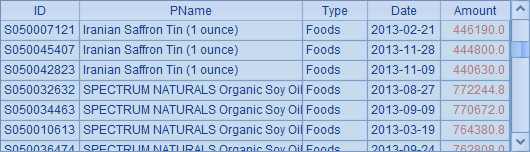
在这段代码中,A7中获得最终结果后,同样应该清除不再使用的格值。在清除格值时,除了前面介绍的指定单元格或区域,还可以指定区段的主格,如:
|
|
A |
B |
|
1 |
[Order_Appliances.txt,Order_Foods.txt] |
=[0]*A1.len() |
|
2 |
for A1 |
=file(A2).import@t() |
|
3 |
|
=B2.top(100,-Amount,~) |
|
4 |
|
=B3.sort(PName) |
|
5 |
|
>B1(#A2)=B4 |
|
6 |
=B1.merge(PName) |
|
|
7 |
=A6.new(ID, PName,Type,Date,Amount) |
clear A1:B1,A2:,A6 |
B7的clear命令中,A2:的写法和单元格区域类似,但没指定区域的结束格。这样的写法表示清除以A2为主格的区块中所有单元格的值,即清除第2~5行的所有单元格的格值。执行后,除了A7中的结果,其它单元格中的格值都被清除。