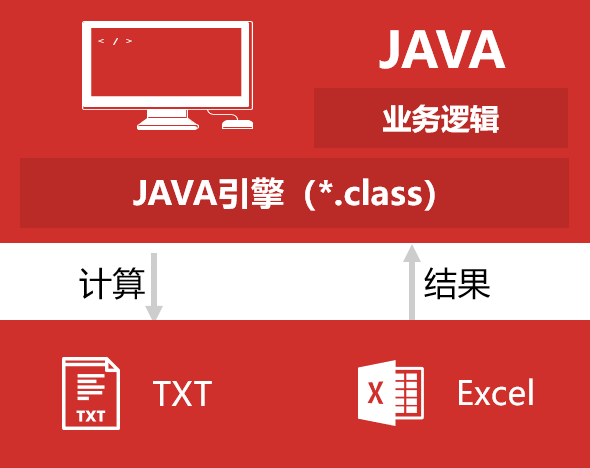
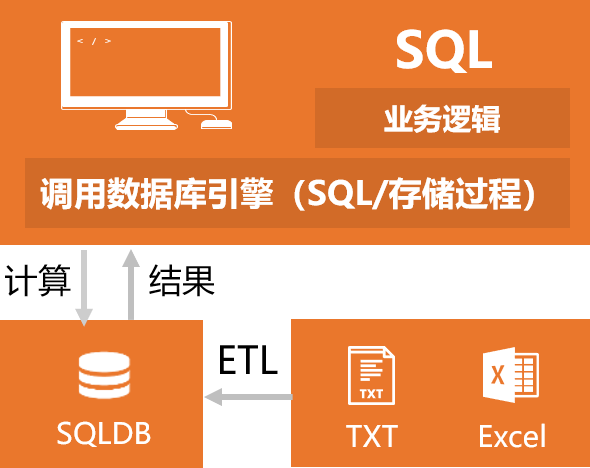
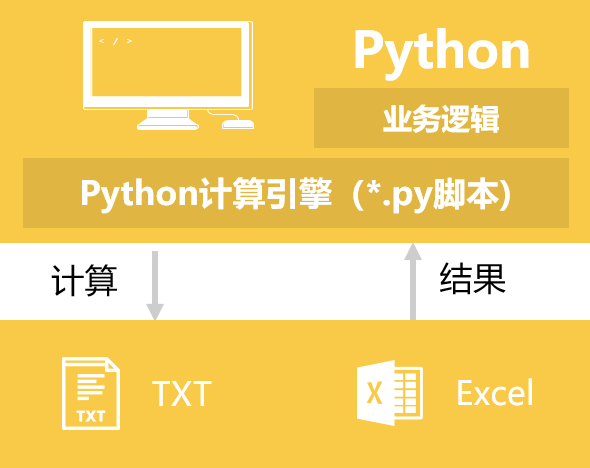
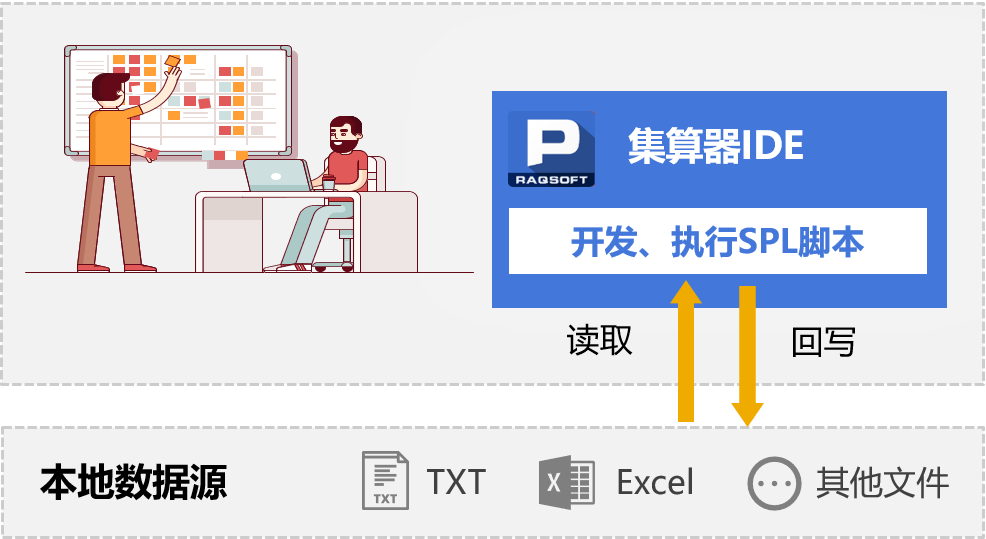
经常面对这类任务?
- 对着500多个Excel做同样的汇总统计
- 去除文本文件里的重复行
- 对比两个csv有啥差异
- 几十个Excel合并起来,把大Excel拆成多个小的
- 几个Excel的数据要用同一个列关联起来
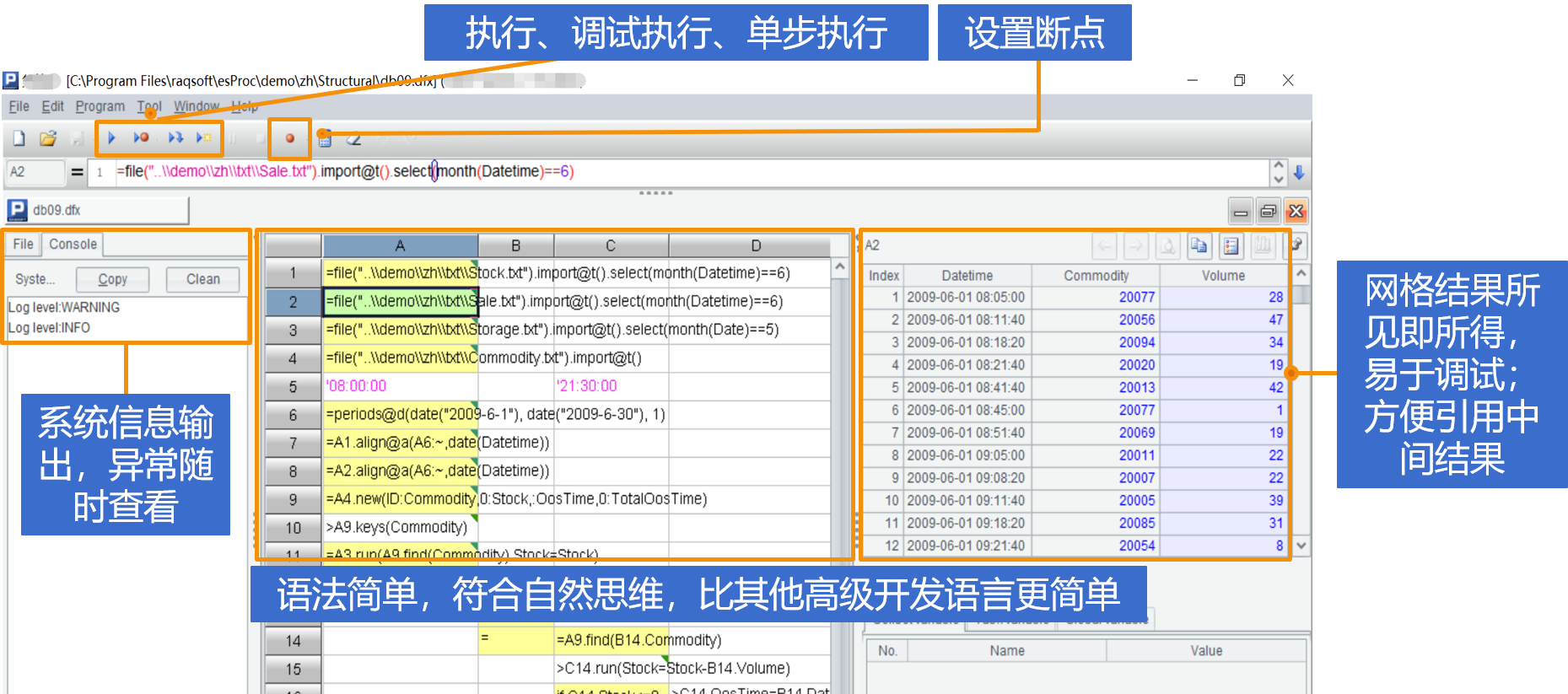
| 1 | import pandas as pd |
| 2 | def iterate(col): |
| 3 | prev = 0; |
| 4 | res = 0; |
| 5 | val = 0; |
| 6 | for curr in col: |
| 7 | if curr – prev > 0: |
| 8 | res += 1; |
| 9 | else: |
| 10 | res = 0; |
| 11 | prev = curr; |
| 12 | if val < res: |
| 13 | val = res; |
| 14 | return val; |
| 15 | data = pd.read_excel('D:/Stock.xlsx',sheet_name=0). sort_values('Date').groupby('Company')['Price'].apply(iterate); |
| A | |
|---|---|
| 1 | =file("D:/Stock.xlsx").xlsimport@t().sort(Date).group(Company) |
| 2 | =0 |
| 3 | =A1.max(A2=if(Price>Price[-1],A2+1,0)) |
集合运算领域专业语法,同样过程代码更简洁!
| A | |
|---|---|
| 1 | $SELECT * FROM D:/Stock.xlsx WHERE Company='0001' ORDER BY date |
| 2 | $SELECT Company,max(price),min(price) from D:/Stock.xls WHERE month(date)=1 GROUP BY Company |
| 3 | $SELECT Company.Name,Stock.date,Stock.price FROM D:/Stock.xls Stock LEFT JOIN D:/Company.txt Company ON Stock.company=Company.ID |
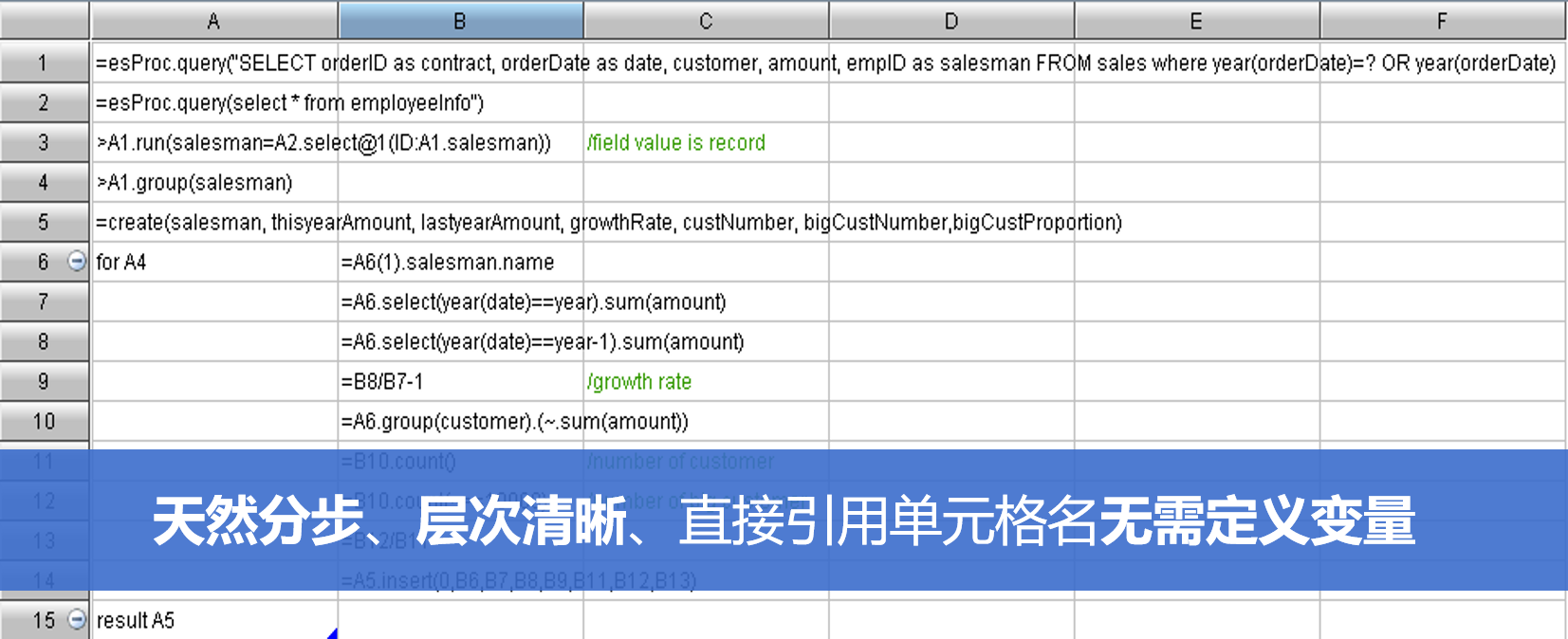

| Old.csv | New.csv | |
| userName,date,saleValue,saleCount | userName,date,saleValue,saleCount | |
|---|---|---|
| 1 | Rachel,2015-03-01,4500,9 | Rachel,2015-03-01,4500,9 |
| 2 | Rachel,2015-03-03,8700,4 | Rachel,2015-03-02,5000,5 |
| 3 | Tom,2015-03-02,3000,8 | Ashley,2015-03-01,6000,5 |
| 4 | Tom,2015-03-03,5000,7 | Rachel,2015-03-03,11700,4 |
| 5 | Tom,2015-03-04,6000,12 | Tom,2015-03-03,5000,7 |
| 6 | John,2015-03-04,4800,4 |
| A | B | C | |
|---|---|---|---|
| 1 | =file("d:\\old.csv").import@ct() | =file("d:\\new.csv").import@ct() | /逗号分隔的文本 |
| 2 | =new=[B1,A1].merge@od() | /求差集 |
| Customer ID | Customer Name | Invoice Number | Amount | Purchase Date |
|---|---|---|---|---|
| 1234 | John Smith | 100-0002 | $1,200.00 | 2013/1/1 |
| 2345 | Mary Harrison | 100-0003 | $1,425.00 | 2013/1/6 |
| 3456 | Lucy Gomez | 100-0004 | $1,390.00 | 2013/1/11 |
| 4567 | Rupert Jones | 100-0005 | $1,257.00 | 2013/1/18 |
| 5678 | Jenny Walters | 100-0006 | $1,725.00 | 2013/1/24 |
| 6789 | Samantha Donaldson | 100-0007 | $1,995.00 | 2013/1/31 |
| A | B | C | |
|---|---|---|---|
| 1 | for directory@p("d:/excel/*.xlsx") | =file(A1).xlsopen() | /循环目录下每个Excel |
| 2 | =B1.conj(B1.xlsimport@t(;~.stname)) | /循环每个sheet | |
| 3 | =@|B2 | /依次合并sheet | |
| 4 | =A4.groups (month('Purchase Date'):Month;sum(Amount):Total,avg(Amount):Average) |
/分组汇总 | |