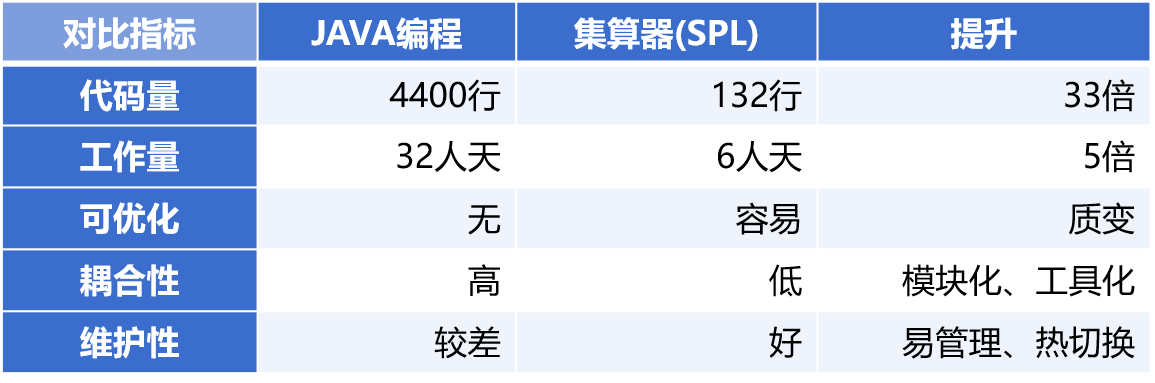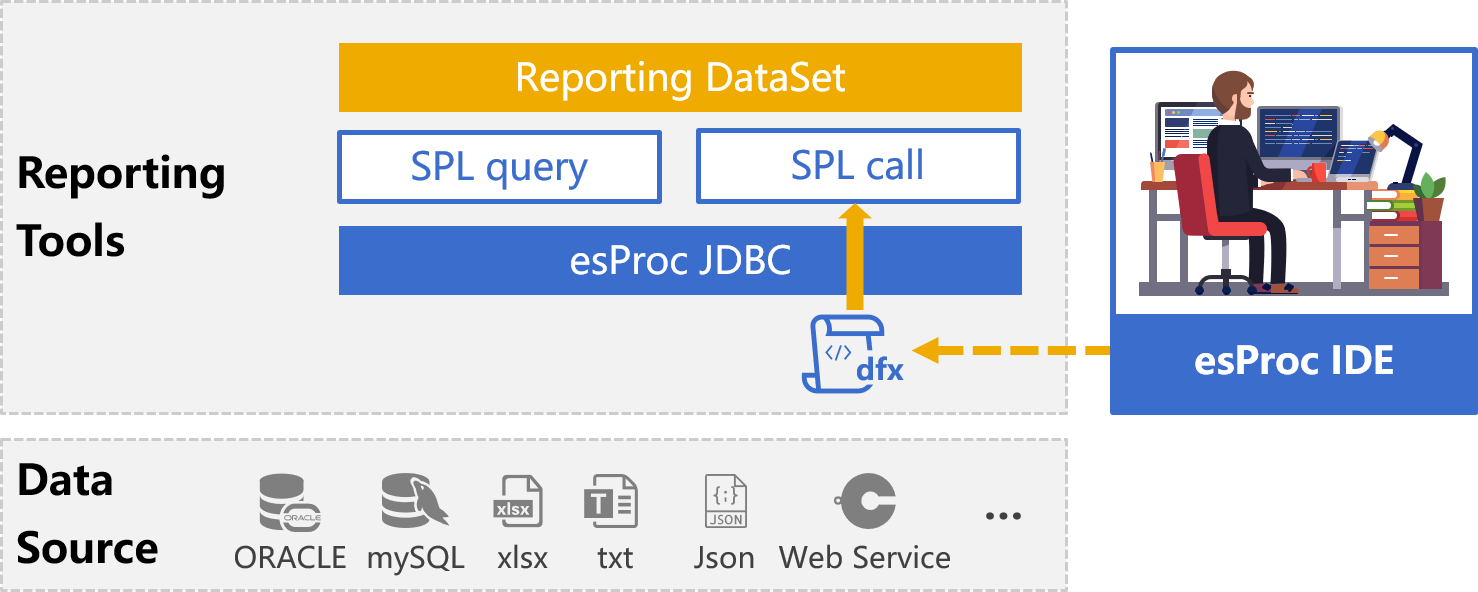
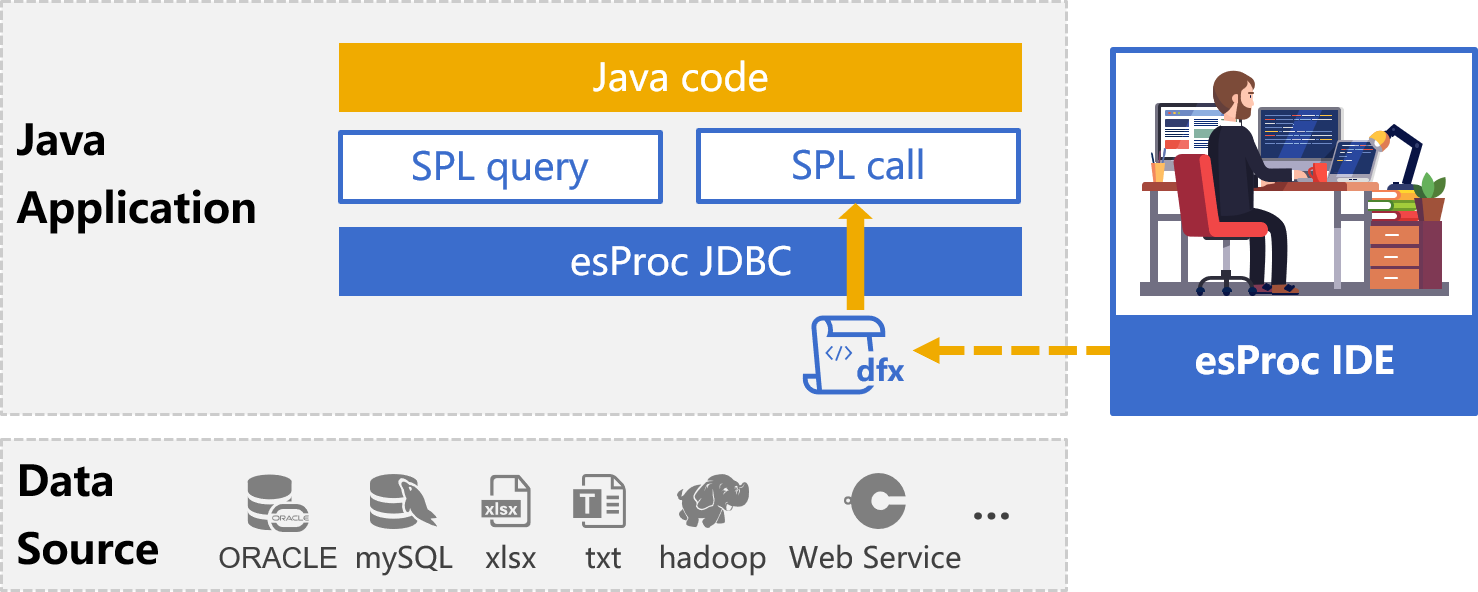

示例某支股票最长连续涨了多少交易日?
| 1 | import pandas as pd |
|---|---|
| 2 | def iterate(col): |
| 3 | prev = 0; |
| 4 | res = 0; |
| 5 | val = 0; |
| 6 | for curr in col: |
| 7 | if curr – prev > 0: |
| 8 | res += 1; |
| 9 | else: |
| 10 | res = 0; |
| 11 | prev = curr; |
| 12 | if val < res: |
| 13 | val = res; |
| 14 | return val; |
| 15 | data = pd.read_excel('D:/Stock.xlsx',sheet_name=0). sort_values('tradeDate').groupby('Company')['closePrice'].apply(iterate); |
| 1 | select max(continuousDays)-1 |
|---|---|
| 2 | from (select count(*) continuousDays |
| 3 | from (select sum(changeSign) over(order by tradeDate) unRiseDays |
| 4 | from (select tradeDate, |
| 5 | case when closePrice>lag(closePrice) over(order by tradeDate) |
| 6 | then 0 else 1 end changeSign |
| 7 | from stock) ) |
| 8 | group by unRiseDays) |
| A | |
|---|---|
| 1 | =stock.sort(tradeDate) |
| 2 | =0 |
| 3 | =A1.max(A2=if(closePrice>closePrice[-1],A2+1,0)) |
Vertica不支持存储过程,复杂业务逻辑只能用Java写,代码冗长不易维护

Excel种类多达44种,由Java解析数据入库,开发周期长,硬编码难度高
全部44种Excel解析由原来的32人天下降到6人天
每种Excel解析代码量由100行变为3行
除代码量简短易维护外;脚本热部署即修改即生效