集算器 产品特性
敏捷语法与内置数据对象
使用集算器,用户可以基于自然思维过程书写代码,无需更换思路即可将复杂的业务逻辑快速转换为实际代码。完成同样的计算,集算器比JAVA和SQL简短数倍。
比如:某只股票最长连续涨了多少个交易日?典型的SQL语句如下:

使用集算器的敏捷语法,对应的代码如下:

与一般文本式代码不同,集算器的代码书写在网格中,如下图:
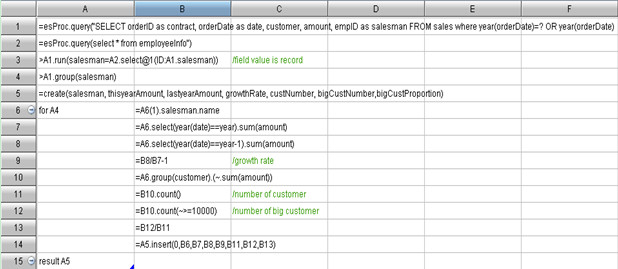
集算器提供类Excel网格式界面,执行顺序从左至右、由上至下,每个单元格由对应的行号列号命名,因此用户可以直接引用单元格名而无需定义变量。
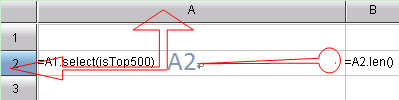
网格式界面的天然格式化,自动对齐,代码自动缩进,从而省去了排版工作。网格式代码不仅使代码整洁干净,而且提供了直观的方式来观察计算步骤。
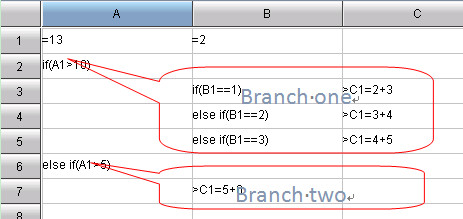
网格代码天然支持分步。它允许用户按照人脑的思维习惯,从业务角度出发,边观察边思考边书写,逐步地解决问题。这样,复杂的计算目标可以分解为多个步骤,每一步都可以引用之前的计算结果而且更易于评估和纠错。
SQL不支持分步式计算,因而计算的复杂度直线上升。JAVA/VB等高级语言支持分步计算,但对结构化数据计算的支持不够丰富,不属于数据库计算类的语言。集算器则兼具两者的优势,而语法更加简单。
集算器具有丰富的库函数,支持分组、循环、排序、过滤、集合运算、有序集合、
分组和循环:
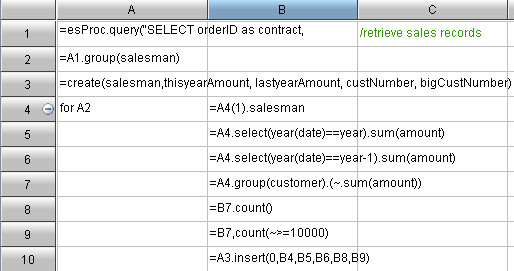
上图中,A4是循环语句,B4-B10是循环体内部。
集算器支持基本分组、对位分组、枚举分组。和SQL不同,集算器分组后的数据是以集合的形式存在的,集合中的每个成员都是泛型,可以对应一组数据。分组和汇总还可以分步计算,分组结果因此可以重用。
排序和过滤是结构化数据中典型的算法,集算器为此特别设计了方便易用的循环函数。循环函数可以减少大多数循环语句的使用,从而可以降低编程难度,提高开发效率。
集合运算:
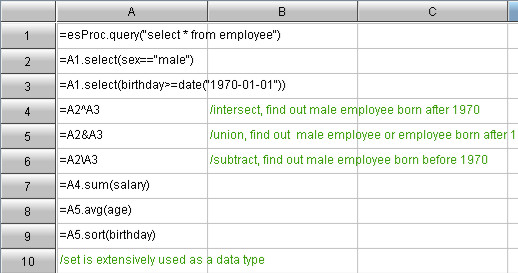
集算器支持集合的和(concatenate)、并(union)、交(intersection)、差(Difference)、乘(multiply)、对位运算(alignment operation)、对位比较(aligning comparison)、集合比较(compare)等运算;也支持按序号正向或反向取成员、子集、反向排列成员、复制、转置矩阵等算法。
有序集合:

有序是指数据按照一定的顺序存放,每条数据每个成员都有绝对或相对的编号,可以通过序号访问数据,方便地对数据进行有序操作,比如:定位、排名、排序。
集算器支持有序集合,使用序号可以更轻松地访问集合的成员并进行和顺序相关的计算。有序计算属于SQL的典型难题,如相对位置访问,即:指相对于当前记录(组)的前几位(组)或后几位(组)。使用集算器的有序集合,这类问题可以轻松解决。
集算器分步计算可以使观察中间结果更方便,调试代码也更加容易,开发效率大大提高。
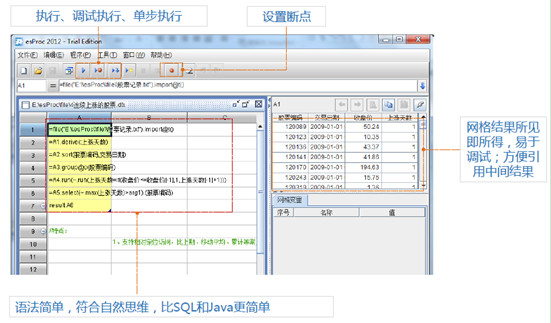
集算器支持完备的调试功能,包括:设置断点、执行到断点、执行到光标、单步执行。相比之下,SQL不直接支持分步,因此难以观察中间结果,难以化简计算,难以调试。
多样性数据源
集算器支持不同数据源之间的计算,并可将计算结果写回多个或单一的数据源。集算器支持关系型数据库,也支持MongoDB,Cassandra等NoSQL数据库。集算器提供了大量函数处理结构化数据,同时也支持半结构化数据的计算。集算器可直接访问本地和局域网的文件数据,还可以无缝访问HDFS等分布式文件系统,它支持通用性较好的txt/excel文件,也支持性能较好的私有格式的文件。
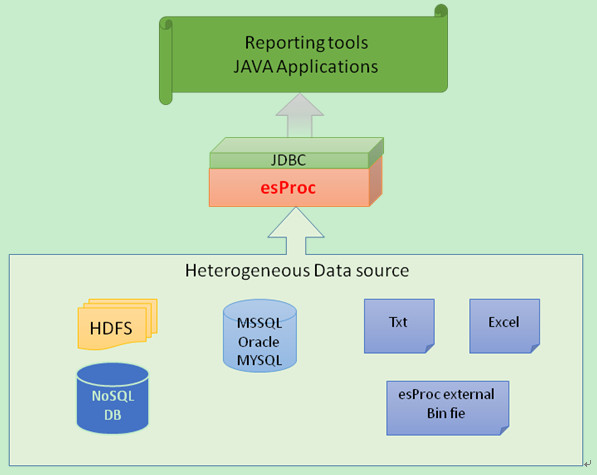
关系型数据库: 集算器支持所有具备JDBC接口的数据库,比如Oracle、MSSQL、MYSQL、DB2等。
文本数据源:集算器支持结构化的文本数据源,文件中的行分隔符和列分隔符可自由定义。比如*.txt ,*.log等文件。集算器也直接支持各版本的Excel文件,以及私有格式的二进制文件。
无缝访问HDFS:集算器内置读写HDFS的函数,访问路径符合HDFS习惯。集算器支持多线程并行计算,可以使用游标方式读写并计算HDFS中的大数据文件。
NoSQL数据库:对于提供了JDBC驱动的NoSQL数据库,集算器同样可以访问,比如: Hbase、Cassandra等。集算器还提供了MongoDB专用函数,可以用MongoDB的查询语法直接访问数据。
半结构化数据:集算器提供了第三方编程接口,用户可以开发自定义集算器函数,以解析XML、SOAP或其他形式的半结构化数据。自定义函数与集算器固有的函数在使用上并无区别,同样可以进行结构化数据的计算。
除了读取,集算器的计算结果也可以回写进原数据源或不同种类的数据源,也可以同时写入多个数据源。同样的,集算器内置了回写各种数据源的函数,既支持单记录的修改,也支持批量数据整体回写。
由于向上级应用程序提供了一致的JDBC接口,集算器因此可以和数据源共同组成易用的hybrid database。以往的多数据源计算需要高端报表工具、难以维护的ETL、昂贵的数据仓库来实现。集算器不绑定特定的数据源,天生支持多种数据源的混合计算,它可以降低NoSQL和传统数据库的结合难度;可以解除单源报表的限制;可以让JAVA应用轻松面对日益复杂的数据环境。
并行大数据计算
集算器支持TB级数据计算,只需书写简单的代码,就可以用集算器实现多线程并行计算,大任务可被拆分为多个小任务同时执行,以此来充分发挥计算机软硬件性能。
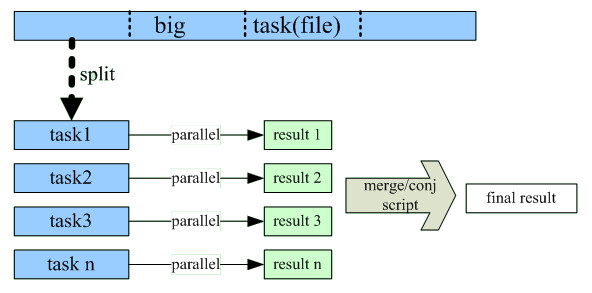
集算器封装了并行计算语句,使之更适合进行结构化数据计算,写法也更加直观简单。集算器可以根据字节数将文件拆分为大致相等的几部分,并同时进行计算,不仅拆分速度快,而且能自动进行取头补尾的工作,使拆分后的数据保持整行。各线程完成计算后,集算器提供了方便的函数对结果进行合并、归并,或进一步加工。
集算器提供了并行函数,由计算器引擎自动设置并行数量,其用法和普通函数相同,但性能更高。程序员也可以自由选择优化路径,比如根据数据量、CPU核心数、硬盘转度来合理拆分任务,使用fork语句自由设置线程数,使用游标函数从文件读取指定数量的记录,并转为内存计算。可控的优化路径有助于挖掘硬件的最大性能。
集算器对底层函数进行了优化,配合并行计算可进一步提高性能。
读取外存大文件时,集算器无需进行数据流到对象的转换,比JDBC性能更高。遍历数据时,集算器函数的执行效率高于数据库解释器,比Perl等脚本语言性能更高。进行内存关联计算或有序复杂计算时,集算器使用序号而不是哈希算法做对应,比传统数据库性能更高。
除了单机多线程并行计算,集算器也支持多节点可横向扩展的并行计算。集群中的节点可以根据需要自由增减,发起任务的节点也可由程序员自由更换和指定。一台节点机既可以充当sub,也可以作为main继续向下级节点分发任务,由此可形成多层嵌套的调用关系。
高性能
集算器针对结构化数据优化了算法,支持内存计算、外存计算、并行计算、有序算法,程序员可以根据数据特点和算法特点自由选择优化路径,可以获得比传统数据库和Perl等脚本语言更高的性能。
集算器读取6 colmns, 890M的文件,并以Oracle JDBC作为对比。
硬件环境:PC, Core(TM) i5-3450(4核)共计4线程, RAM 16G, SSD
软件环境:CentOS 6.4, JDK 1.6, Oracle 11g,集算器 3.1
注:测试结果单位为秒,各项测试均有对应的测试报告。

可以看到,集算器比Oracle JDBC速度快一倍以上,原因是Oracle JDBC需要做数据流的对象转换;而集算器是基于Java的,不需要再做数据流的对象转换。因此采用集算器外存文件方案比Oracle JDBC的吞吐性能要好得多。
遍历6 columns, 25G大文件,算法采用分组汇总和查找过滤,分别比较单任务、2任务、4任务、8任务、16任务时的性能,以Oracle做为对比。
硬件:T610, CPU Intel Xeon E5620*2, RAM 24G, HDD Raid5 800G
软件:CentOS 6.4, JDK 1.6, Oracle 11g,集算器 3.1
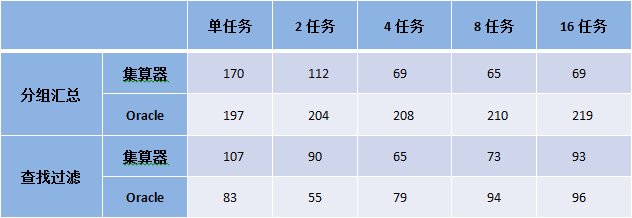
开启并行选项后,Oracle在大数据量(超过内存)时不明显;集算器并行(1到4并行)性能提升明显。
4并发遍历大文件,单任务4G,总数据量16G,算法采用分组汇总和查找过滤,分别比较1并行、2并行、4并行时的性能。以Oracle作为对比。
硬件:PC, Core(TM) i5-3450(4核)共计4线程, RAM 16G, SSD
软件:CentOS 6.4, JDK 1.6, Oracle 11g,集算器 3.1
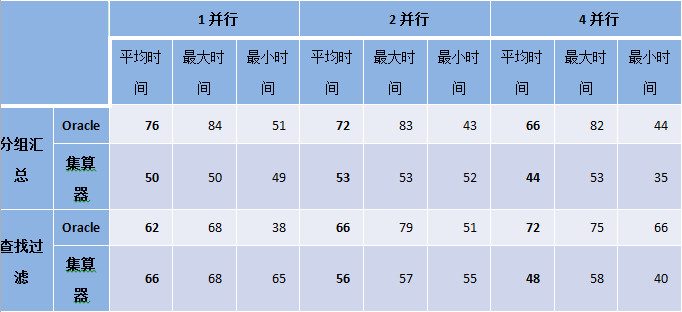
当总任务数据量大于可用内存时,如果采用并行计算方式,集算器的性能好于Oracle。同样条件下,集算器计算时间比较稳定,Oracle最大和最小计算时间之间差别较大。
处理6 column,28G文本文件,比较集算器单任务、JAVA程序、Perl程序、集算器4并行的性能。
硬件:PC, Core(TM) i5-3450(4核)共计4线程, RAM 16G, SSD
软件:CentOS 6.4, JDK 1.6,Perl,集算器 3.1

可以看到,在单线程情况下,集算器作为一种被Java解释执行的语言,与Java本身相比,性能损失并不是十分显著;而同样是解释执行语言,基于Java的集算器比基于C的perl性能还略胜一筹。
借助多线程结构技术,集算器能够大幅度提高性能,而且代码非常简单,Java采用多线程显然也会更快,但代码复杂度很高。Perl则没有多大的优势,单线程性能一般,多线程代码复杂。
综合来看,集算器用于文本处理时,在性能和代码简单性两方面的实用性都足够。
测试集算器6 columns,800万行内存计算的性能,算法采用简单普通计算和复杂关联计算,并以Oracle作为对比。
硬件:PC, Core(TM) i5-3450(4核)共计4线程, RAM 16G, SSD
软件:CentOS 6.4, JDK 1.6, Oracle 11g,集算器 3.1
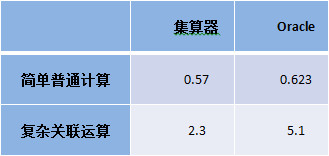
在进行无关联计算简单时,集算器与Oracle基本相当;复杂关联计算时,集算器比Oracle快很多。这是因为集算器使用指针定位来完成外键引用,无须做Hash计算和查找对应,而Oracle要使用Hash算法实现JOIN,
在内存充足时,如果事先能将要运算的数据读入内存并准备好,使用集算器将可能获得比传统关系数据库更好的性能,因此集算器可适用于高性能内存计算。
测试集算器多步骤的脚本运算性能,数据分为6 colmuns 400万行和6 columns 2.4亿行,以Oracle存储过程做对比。
硬件:PC, Core(TM) i5-3450(4核)共计4线程, RAM 16G, SSD
软件:CentOS 6.4, JDK 1.6, Oracle 11g,集算器 3.1
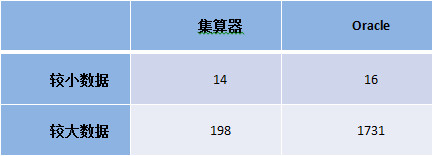
可以看到,当数据较小可以一次装入内存时,集算器和Oracle计算性能相当。数据较大不能一次装入内存时,集算器取数、计算性能都远远好于Oracle存储过程,这是由于Oracle存储过程解释器的性能较差。
在实际应用中,常会遇到复杂运算无法用SQL直接写出而必须用存储过程逐条读出再处理,这种情况下将数据移至库外后并集算器完成会得到更高效率。
易集成性
集算器是纯JAVA产品,天生具备优秀的集成性。集算器分为JDBC、Command line、Server、IDE四个部分,其中JDBC是集算器专门提供给应用程序的调用接口。集算器 JDBC的调用方式和普通数据库的存储过程相同,即JDBC URL\ ResultSet方式。它可以被报表工具和JAVA程序直接集成,作为含有复杂、跨库、高性能计算任务的数据源。
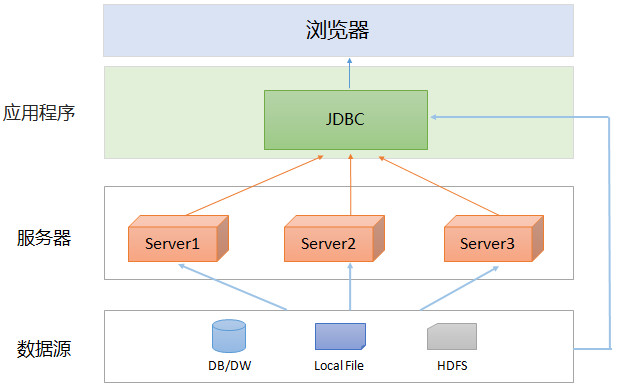
大部分报表工具直接支持JDBC,比如BIRT、Crystal Report、JasperReport等,可以无缝集成集算器,无需为集成书写代码。用户可以先在集算器脚本中完成数据源的计算,再在报表工具中通过 JDBC调用集算器脚本文件,集算器的计算结果将作为标准的存储过程数据源参与报表设计。通过这种方式,报表中复杂的数据源计算转移到集算器中了,而报表工具可以更专注于展现。
同样的通过JDBC Driver,用户可以将集算器高性能计算的结果或大数据量并行计算的结果集成进报表和JAVA代码中。
对比理解
集算器与程序设计语言
集算器不是面向对象语言。
集算器是一种数据计算语言,它具有强大的序表和游标数据对象,专门对(半)结构化数据的计算进行了优化,可以轻松应对各类复杂的计算问题。因为专注于计算,所以集算器结构简单易于理解,用户可以轻松适应它的集成开发环境,并能轻松掌握它的开发方法。集算器不是面向对象语言,没有继承重载等复杂的概念。集算器不能开发完整的应用,只擅长处理应用程序中的计算环节,比如报表数据源准备、JAVA结构化计算类库、计算中间件。
集算器面向应用程序员。
集算器具备敏捷语法、网格风格脚本、完备的调试功能,更适合应用程序员进行步骤多算法复杂的商业计算或者数据源多样的混合计算。相对地,集算器不适合系统程序员进行系统底层开发或完整的工具软件开发。使用集算器,程序员可以更专注于业务理解而非技术实现,有效降低从业务逻辑到程序代码的转换难度。
集算器是Java解释执行的动态语言
集算器是纯Java软件,具有Java的集成性和开放性;集算器是动态语言,具有动态语言的敏捷性和灵活性。集算器的性能理论上不会比Java更好,但超过了其他动态语言。集算器针对(半)架构化数据进行了专门的优化,具有丰富的类库以支持数据计算。集算器支持多线程并行计算,只需书写简单代码就能获得更高的性能。
集算器与SQL
两者都有完备的批量结构化数据计算能力
SQL适合一步可达的简单查询,集算器适合实现复杂多步的业务逻辑。
集算器对SQL的优势
集算器对结构化数据的计算进行了优化,支持分步计算、更彻底的集合化、有序计算、对象引用,这使结构化数据的计算更加轻松。集算器还允许用户根据任务特点设计合适的算法和数据存储方式,这可以获得更高的性能。
SQL对集算器的优势
SQL具有语法简单一致,通用性强的特点。支持SQL的应用程序非常广泛,资源更加丰富。
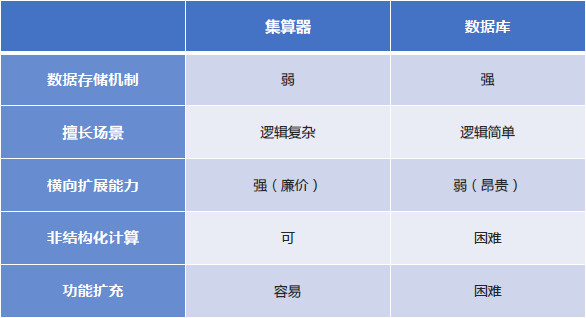
集算器与数据库
集算器不能代替数据库
集算器没有元数据机制,也没有类似SQL的接口语言。虽然集算器有存储功能可以操作数据,但这仅是为了获得更高的吞吐性能。集算器能部分起到数据库的作用,但重点仍在数据计算,并不能替代完整的数据库。
集算器相当于存储过程
集算器可基于数据库、本地文件、分布式文件系统等数据存储方案工作,它的目标是完成复杂过程性计算任务,尤其是传统SQL/SP难以实现的计算任务。本质上讲,集算器是扩展代价更低、性能更好、开发更容易的存储过程。
集算器的开放性更好
集算器具有对外的开放接口,允许用户使用Java语言对其扩展。在外部程序配合下,集算器可以处理非结构化数据;而数据库的体系较为封闭,只能处理结构化数据。
集算器易于横向扩展
集算器易于横向扩展,可部署在普通PC上;而数据库较难横向扩展,一般需要专用的高端设备。
集算器与R语言
集算器与R语言都有类似的敏捷语法和强大的集合运算,能够高效率地完成数据计算方面的开发任务。
R语言为统计分析而设计,提供了丰富的数学函数库,适合完成带有复杂数学模型的算法;而集算器更专业于结构化数据的商业计算,数据库类的计算更为流畅。
R语言主要面向独立工作的数据科学家,集成性不强;集算器有很好的集成性,可以轻松集成到用户的应用程序中。
R语言免费没有并行机制,需要借助其它手段实现大数据计算;集算器内置了多线程并行计算机制,能够直接完成大数据计算。
