【Demo案例】多表关联/聚合——宣传期间销售额最高的员工
步骤
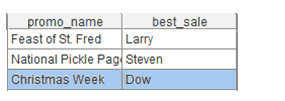
原始数据在数据库的,我们要计算出各个宣传期间内销售额最高的员工都是哪些人

根据一个宣传期的起止时间来过滤数据,按照员工汇总销售额

找到销售额最高的员工并存储起来,继续循环Promotion表,这样就获得了全部结果,如下所示:
步骤
集算器解法

与传统的文本式脚本书写方案不同,集算器脚本是写在网格中的。 传统脚本通常要定义大量变量,取什么变量名?什么类型?放在什么位置?用的时候去哪里找?这些烦恼的问题在集算器中不存在。 在集算器中,格名就是天然的变量名,脚本中可以直接引用格名而无需额外定义。
插入或删除行列时,格名会智能地变迁。 比如在B6上插入一行(假设要对销售额求和):
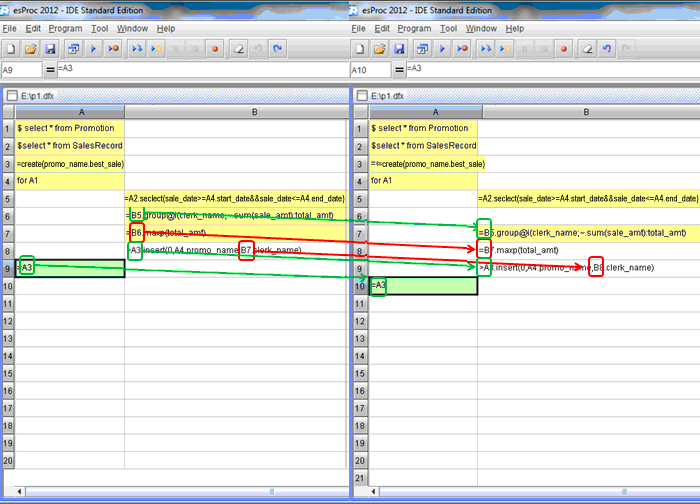
该变的会自动变迁,不该变的保持不变,智能变迁保证了脚本的一致性,可以随意修改而无需额外的工作量
集算器是从左向右,从上至下进行运算的。这种运算方式要比传统风格更直观,可以方便地安排和观察步骤之间的关系,步骤再多也不怕混乱。

网格风格可以使脚本自然缩进,在书写子函数、循环、判断时特别方便。

可以看到缩进自然形成了循环的范围,这比传统风格中的begin….end或{}等方式更为直观和简单
这是另一个集算器脚本,可以看到嵌套循环、常量、注释是如何利用网格来自然对齐的。 传统脚本难以维护的原因之一就是混乱的代码风格。 集算器不存在这样的困扰。

代码特点
下面介绍上述代码中的语法特点:
- 细节:序表
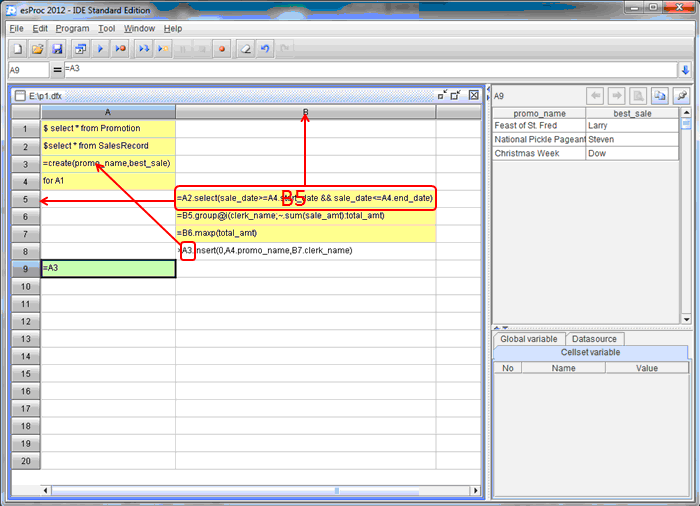
首先请看下例中的A1、A2、A3:

其中:
A1,A2:直接执行SQL
A3:创建空的二维表,将来存放计算结果A1、A2、A3中的数据类型叫做”序表”,它有如下特点:
兼容SQL的结果集
泛型,无须定义字段类型,省去了SQL中table的复杂定义过程。序表广泛存在于集算器的运算中 - 细节:循环语句
请看下例:
 A4:循环定义,遍历A1的成员
A4:循环定义,遍历A1的成员
B5-B8:用缩进自然形成的循环体
B5和B8中用到的“A4”:循环定义所在的单元格就是循环变量,可以直接访问
A9:结束缩进,自然地结束循环体下面解释一下循环体内部的代码:B5:按照Promotion的起止时间过滤SalesRecord,比如第2条纪录的起止时间是2012-11-01到2012-11-07
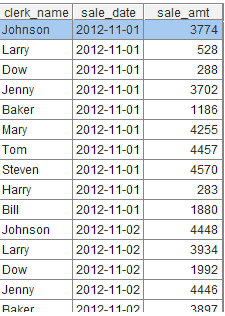
B6:将上一步的结果分组汇总
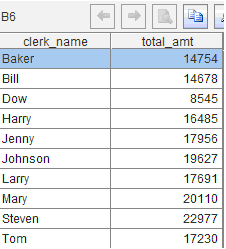 B7:从上一步的结果中找到最大值
B7:从上一步的结果中找到最大值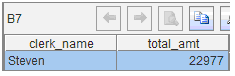 B8:将上一步的结果追加到A3
B8:将上一步的结果追加到A3
- 细节:分步运算
先看下图,回顾一下刚才的步骤:
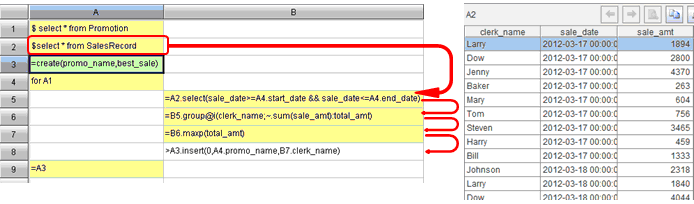
点击A2单元格,在IDE右侧观察A2中的数据。在B5直观的引用A2,继续观察,继续引用上一步的结果集算器的分步运算使复杂的目标轻松被分解为多个简单步骤。 因此集算器特别适合复杂的数据库计算。SQL不直接支持分步,必须一次写出所有的计算过程,代码冗长,容易出错。存储过程支持分步,但它书写繁琐,部署受限,迁移不便,调试复杂,难以观察中间结果。 - 细节:函数选项
先看下图:
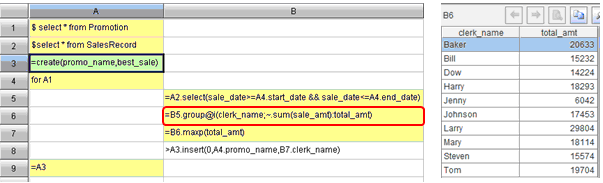
注意一下B6格”@i”的用法,这表示结果中包括分组字段cleark_name,不写@i则不包括分组字段:
 “@i”称为函数选项,集算器用它来扩展函数的功能
类似的,”@1”表示取每个分组的第1条记录;”@z”表示逆序;”@o”表示不排序直接分组。 函数选项的数量少而具有通用性,因此非常易于掌握,比如select函数也可以用@1和@z。”函数+函数选项” 可以在记忆少量函数的基础上就实现大量的功能。集算器具有语法敏捷,表达能力强的优势,它允许用户高效编写代码
“@i”称为函数选项,集算器用它来扩展函数的功能
类似的,”@1”表示取每个分组的第1条记录;”@z”表示逆序;”@o”表示不排序直接分组。 函数选项的数量少而具有通用性,因此非常易于掌握,比如select函数也可以用@1和@z。”函数+函数选项” 可以在记忆少量函数的基础上就实现大量的功能。集算器具有语法敏捷,表达能力强的优势,它允许用户高效编写代码