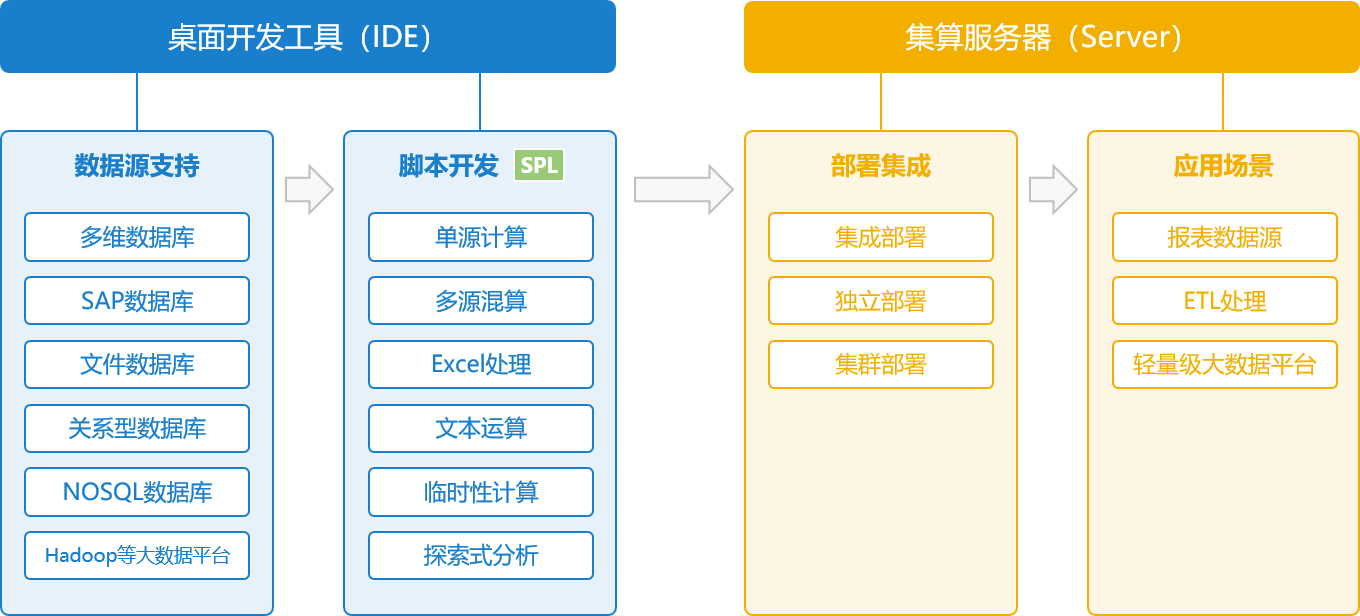
技术架构
优势特征(IDE)
集算器IDE是专门为数据处理和开发设计的编程环境。
IDE1即装即用,易学易用
内置集成了各种外部数据接口,无需为连通不同数据源浪费时间和精力。界面简洁,语法简单,天然分步,轻松调试。
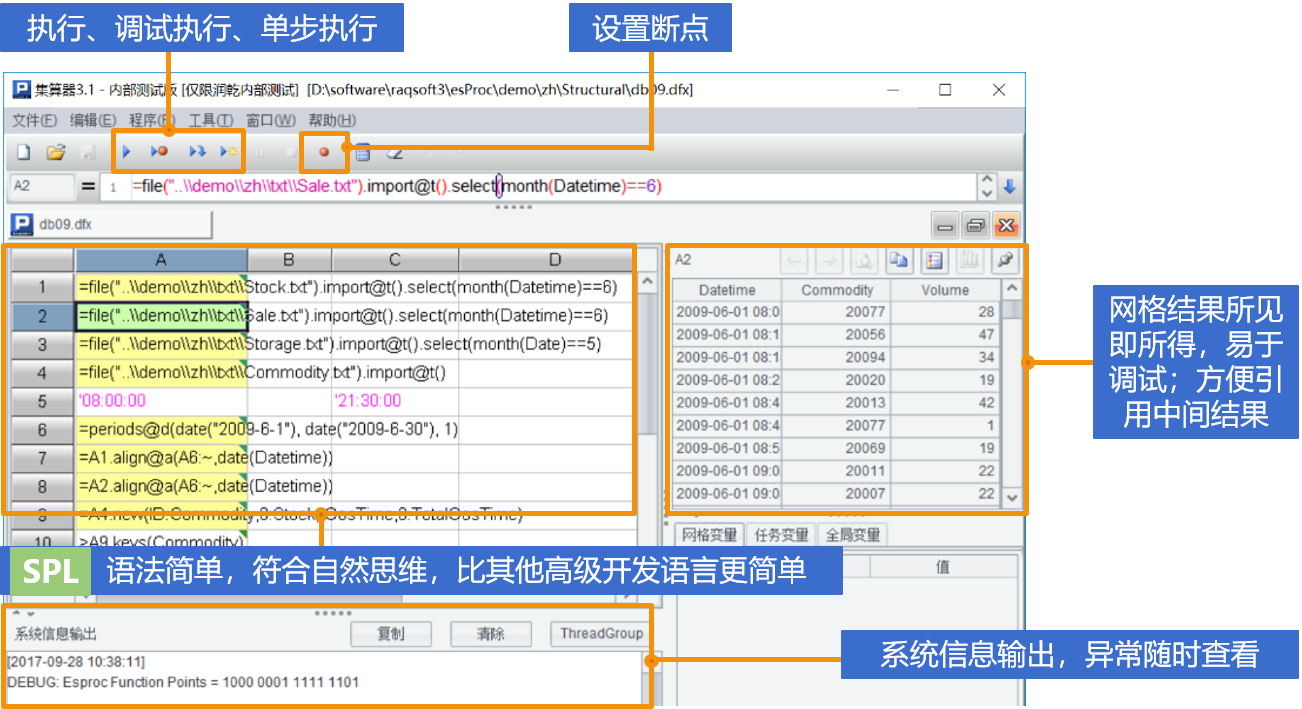
如果你精于Excel,想进一步提升数据分析水平,集算器能最快的助你一臂之力,带领你轻松完成数据获取、数据清洗、数据呈现、数据规模化和自动化的过程,通过短时间练习你会发现,编程来处理数据并不难学,会给你带来更多工作乐趣和幸福时光。
IDE2类库丰富,语法简洁

IDE3特别适合解决复杂运算
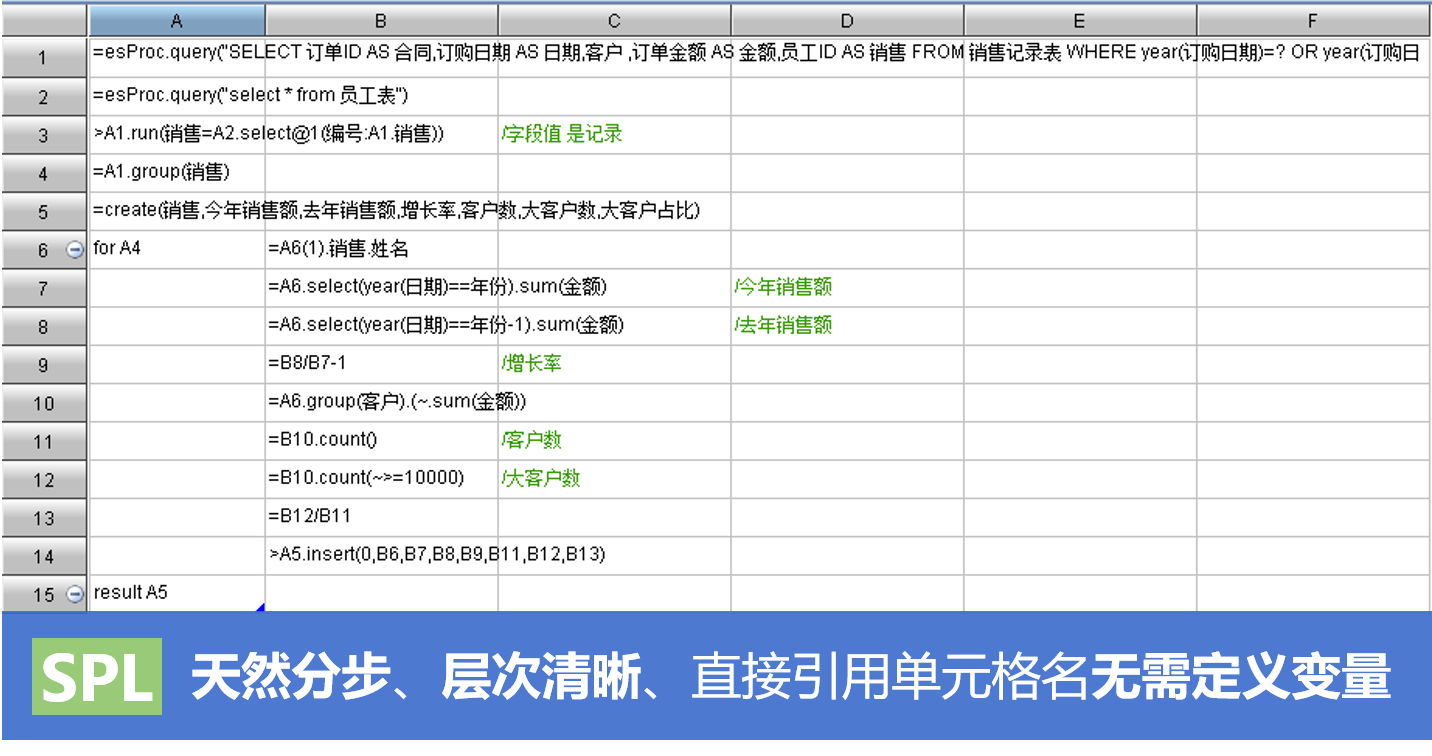
如果你精通SQL,需经常费时、费力的写层层嵌套的SQL,有时甚至还很难写出,集算器是你的福音,分步式处理,轻松引用中间结果,类表的数据结构和熟悉的函数,比Python更容易学习,更容易使用。
应用场景(Server)
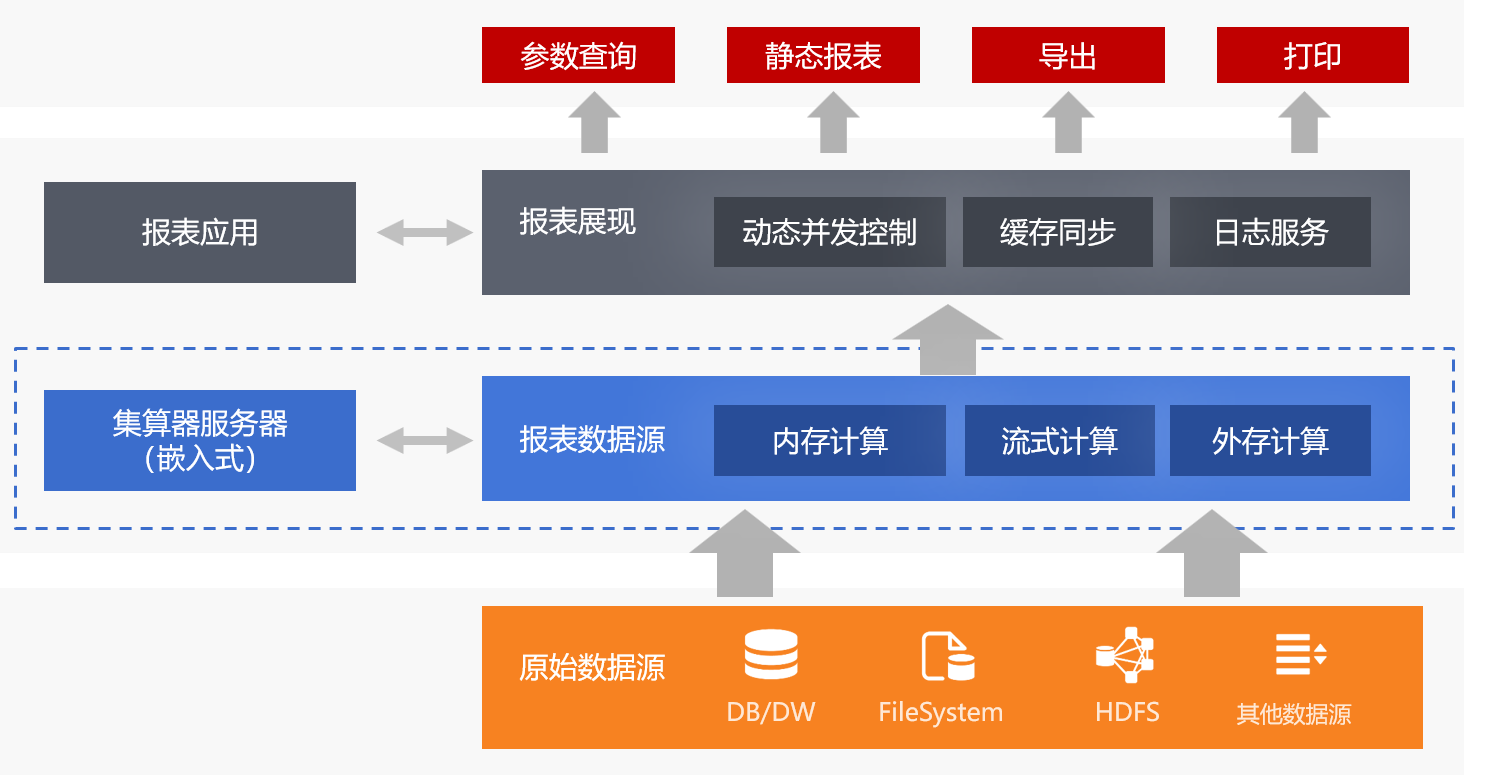
集算器Server是运行在Java平台上的数据计算型中间件,嵌入式接口为工程提供了便利的集成性,服务式接口为工程提供了高效的扩展性。
Server1报表数据源
-
比Java和SQL更易写
当前复杂报表的数据准备工作一般是采用Java或SQL完成的,存储过程以及中间表也可以看作是SQL。集算器的语法比Java和SQL更为简单易懂,采用集算器能在很大程度上简化这些开发量。
-
优化报表应用结构
集算器写出来的脚本类似报表模板的外置文件,不需要和主应用程序一起编译打包,可以和报表模板一起放在文件系统中管理维护。集算器是解释执行的动态语言,如有修改时不需要涉及主应用程序,只要把集算器脚本替换就可以,天然就支持热切换。
-
直接使用多样性数据源
集算器可以计算非关系型数据库和文件数据,直接使用多样性数据源制作报表,这不仅减少了将数据导入关系数据库的开发工作量,而且在应用体系上也更为简单,没必要为了获得更强的计算能力增加多余的关系数据库,成本降低还减少了数据导入过程中导致的不一致风险。
-
提升报表运算性能
为报表应用引入计算型报表数据源,弥补了传统报表工具本身计算能力不足带来的各种性能问题。
通过游标异步加载、多线程并行取数、分步控制SQL执行路径等内置计算技术,简单而有效的解决了常见于大数据报表、T+0报表、多源报表的性能问题。
Server2ETL式批处理
集算器经常用于ETL式计算过程,支持抽取各类关系型和非关系型数据源,可根据数据规模和时效性,灵活采用内存式、流式、外存式计算技术。对于大数据处理,先落地二进制文件,后续计算将更高效和稳定,任务重做也更容易。编程式批处理,尤其适合计算规则复杂的任务流程,可轻松被外部调度工具整合。轻量级架构,从单机并行到多机运行扩展方便、性能线性提升。
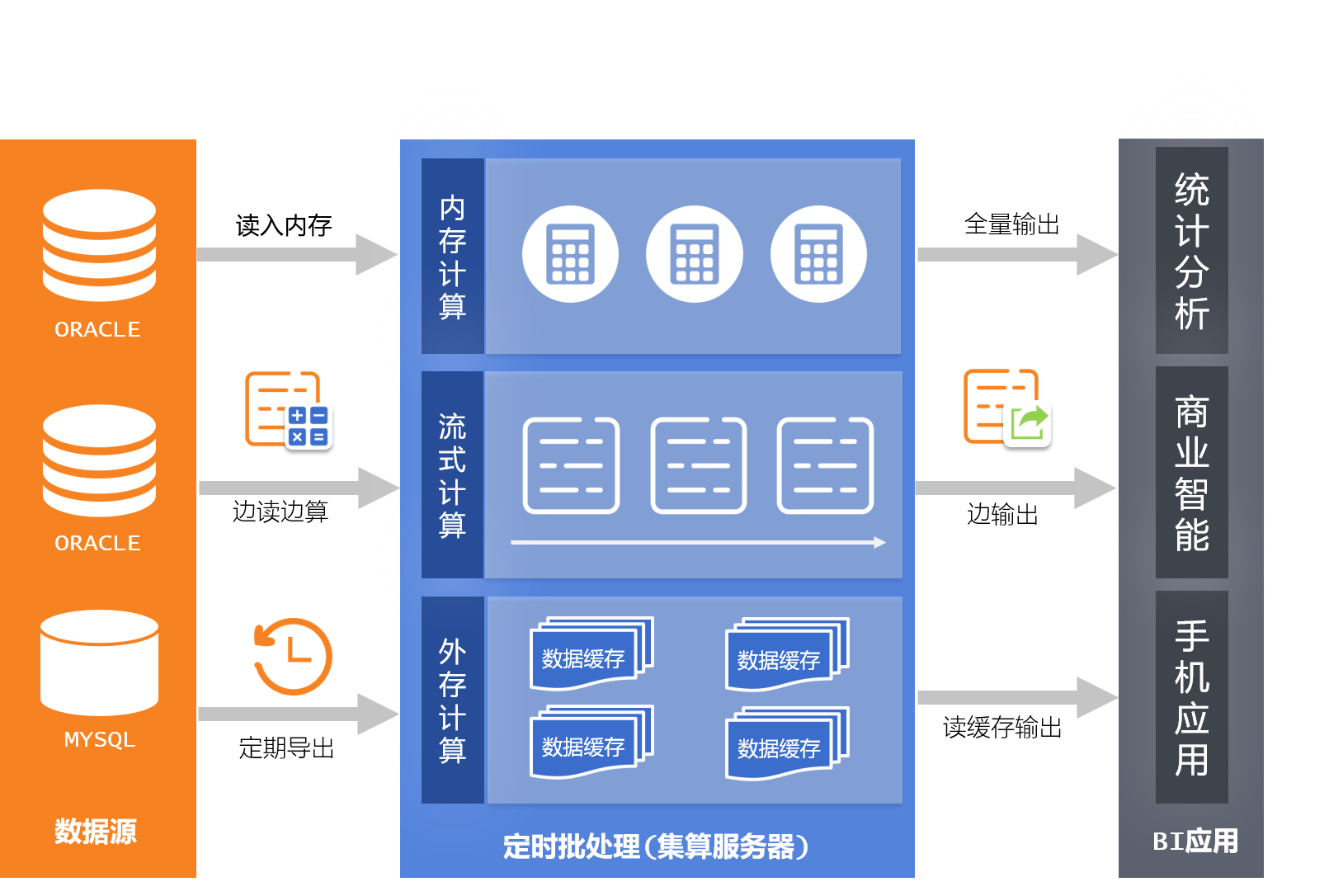
Server3轻量级大数据计算
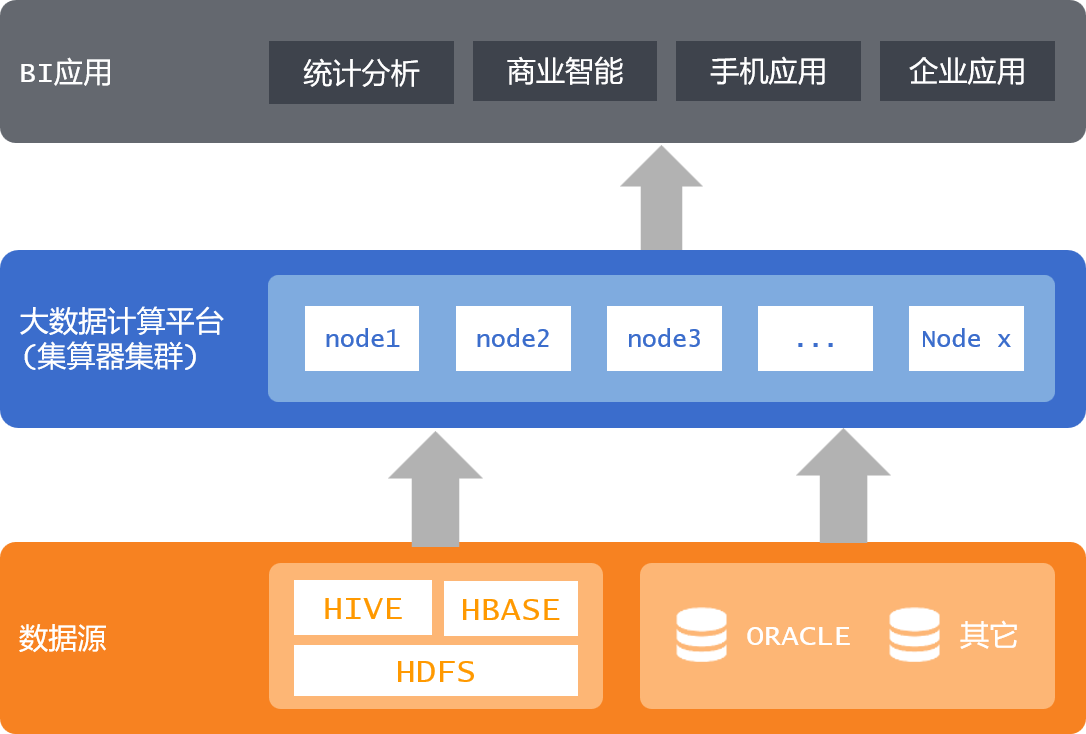
集算器也提供了集群并行机制,没有基于流行的Hadoop体系,拥有独立的存储和计算体系,设计目标是几个到十几个最多几十个节点的中小规模集群,为中小用户提供轻量级大数据解决方案。
集算器集群部署简单、快捷,使用灵活、自主可控,可以针对每个节点进行个性化配置,更有效地利用硬件资源。Hadoop是个庞大的重型解决方案,虽然软件本身开源免费,但要配置用好它并不容易,维护支持成本不低。
集算器集群是个单纯的计算体系,开放、不挑数据源,来自关系数据库、NoSQL数据库、文件数据,包括HDFS文件都可以被集群计算,计算结果也可以再写入这些数据源或直接为上层应用提供数据源。
客户反馈

Hello raqsoft,
We use your product in the Finance industry, especially in group insurance for Cost Control Monitoring.
We do BI with EsProc to connect with multiples databases such as Vertica, MySql, MS Acces, etc…
The best use for us is to pass parameters to the Vertica database.
We are using Birt (Eclipse) as a reporting tool. EsProc is good at manipulating the different media’s used in our reporting tool. It is easy to use, it's like an Excel mix with Sql query that have multiple cells.
Each cell becomes a data array that are easy to use, compare and manipulate. It is very logical and you have made it user friendly.
EsProc is a powerful tool to manage large amounts of data, as all the information can be saved in the internal memory of the server.
Our main concern, was to setup all product together.
EsProc made it simple to integrate the data management with our reports.
Steeve Roy
Vice President, Information technologies
FlexGroup, Canada