润乾全链AI+BI 自然语言查询报表 AI时代的商业智能

什么是AI+BI

使用自然语言直接查询、生成报表
ChatBI的关键两环
① 智能问数
Text2SQL
② 智能报表
Text2Report
当前技术现状
只有查询没有报表
当前几乎所有ChatBI关注点都在前半段,只有Text2SQL和粗线条的报表,缺乏精细的Text2Report

Text2SQL

Text2Report
只能“问数”,“报表”还要依靠传统方式完成
事实上,现在Text2SQL也存在“准确性”问题,第一步还没走完
当前Text2SQL技术的问题 直接生成方式
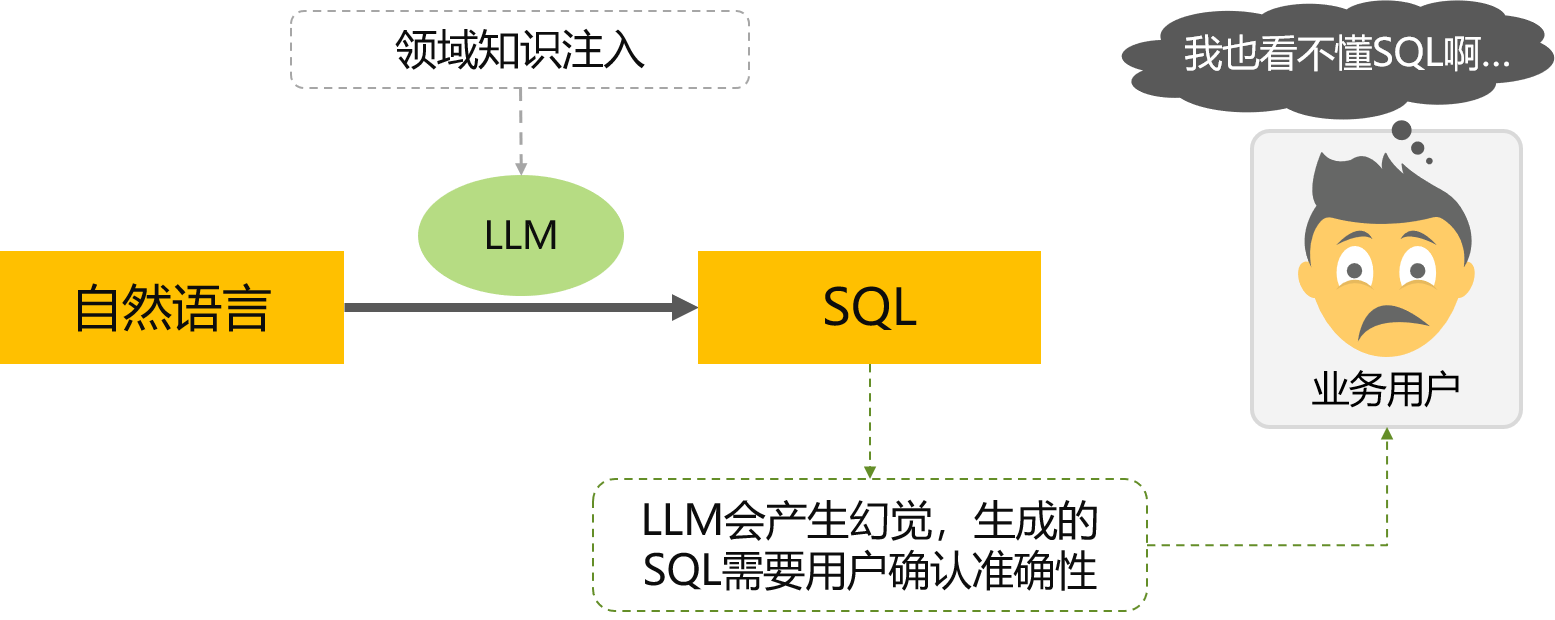
语义错误很难被识别
- 语法错误SQL语法错误,执行的时候会报错,比较容易发现
- 语义错误SQL语义错误,执行也能得到结果,业务人员就很难判断了
- 举例说明LLM会把苹果理解为水果,但用户可能要查询的是手机

缺乏可确认的控幻机制,企业无法接受这种不确定性
当前Text2SQL技术的问题 借助中间层方式
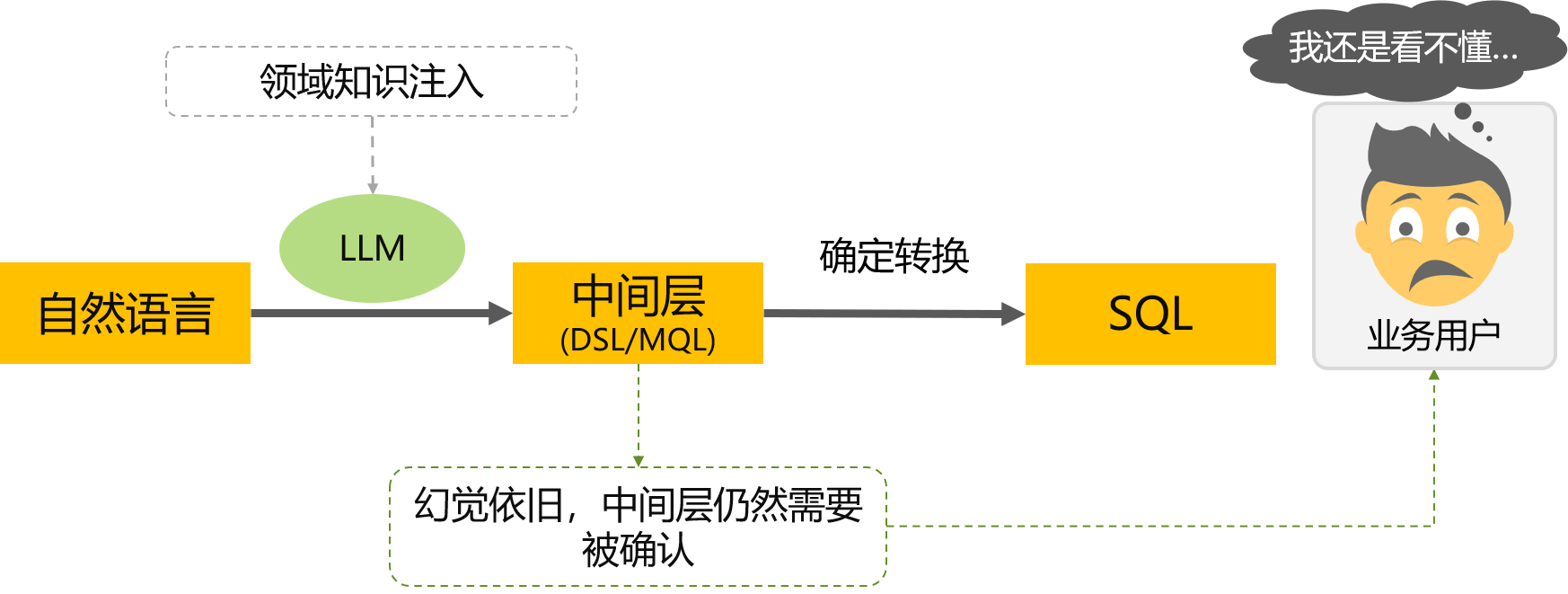
通过“降智”换取一定准确性提升
- 幻觉问题依旧LLM生成MQL仍会产生幻觉
- 有限提升准确性为了提升准确性,不得不将中间层设计得足够简单,导致复杂查询无法实施
- 举例说明比如不支持嵌套查询、多表关联等

准确性提升有限,仍然缺乏可确认的控幻机制,叠加查询能力减弱
大模型获得领域知识成本过高
微调
- 用相关的标注数据对现有模型进行训练
- 微调是黑盒子,很难检查LLM学会了没有,还是学歪了、记混了
- 成本高昂,需要组建专门AI团队(相当于为了坐飞机而建立飞行员团队)
RAG(检索增强生成)或提示工程
- RAG引入的外部知识库存在精度问题,找不到关键领域知识的可能性很大
- LLM更倾向于依赖内部参数,忽略知识库检索结果,会得到错误的查询语句
- 仍然需要专业AI团队,成本高昂
Text2SQL的三难困境
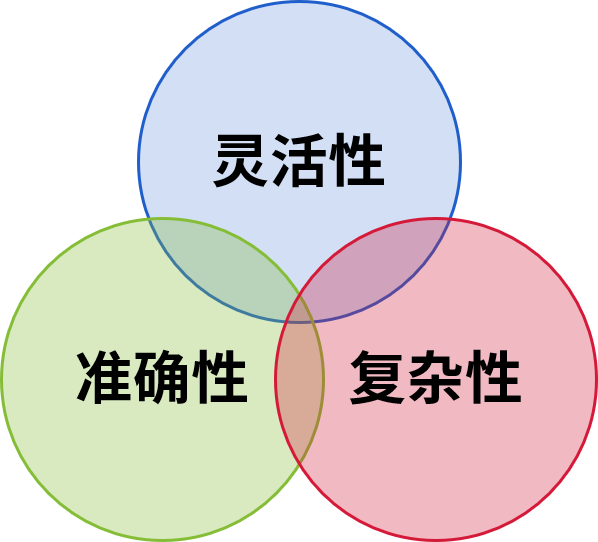
现有技术的不可能三角
- 灵活性:理解多样化表达
- 准确性:生成正确 SQL
- 查询复杂性:支持复杂计算
核心困境:生成的 SQL 或 MQL 均无法被业务用户理解和确认
为什么LLM难以攻克Text2Report
准确性不足,无力延伸

LLM在Text2SQL阶段仍受“幻觉”困扰,准确性问题尚未解决,无力向后端报表延伸
缺少训练数据

多维报表是一连串有状态的操作序列,缺乏训练数据的LLM,难以可靠规划和执行整个流程
润乾全链AI+BI解决方案
- NLQ实现自然语言查询(Text2SQL)
- NLR实现自然语言报表(Text2Report)
产品架构
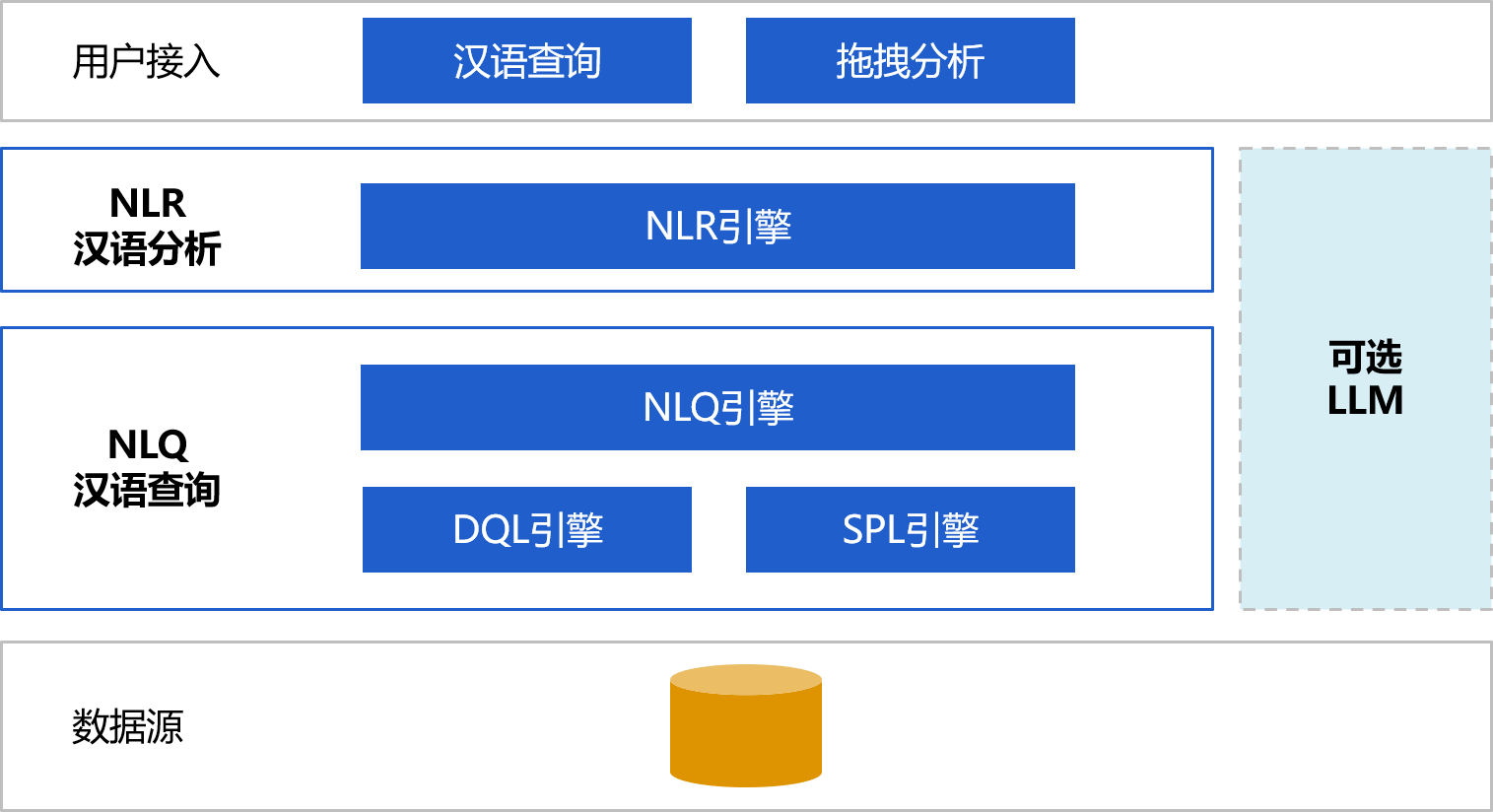
润乾全链AI+BI解决方案
NLQ Text2SQL
NLR Text2Report
润乾NLQ是什么?
- 创新Text2SQL技术
- 面向业务人员,自然语言表达
- 兼得灵活性/准确性/查询复杂性
- 全链AI+BI的第一个环节
NLQ: Natural Language Query
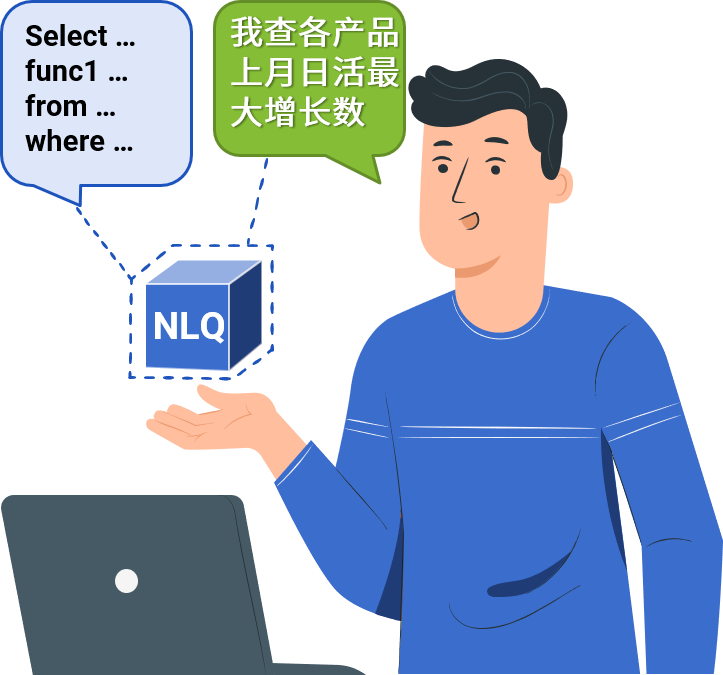
NLQ处理流程
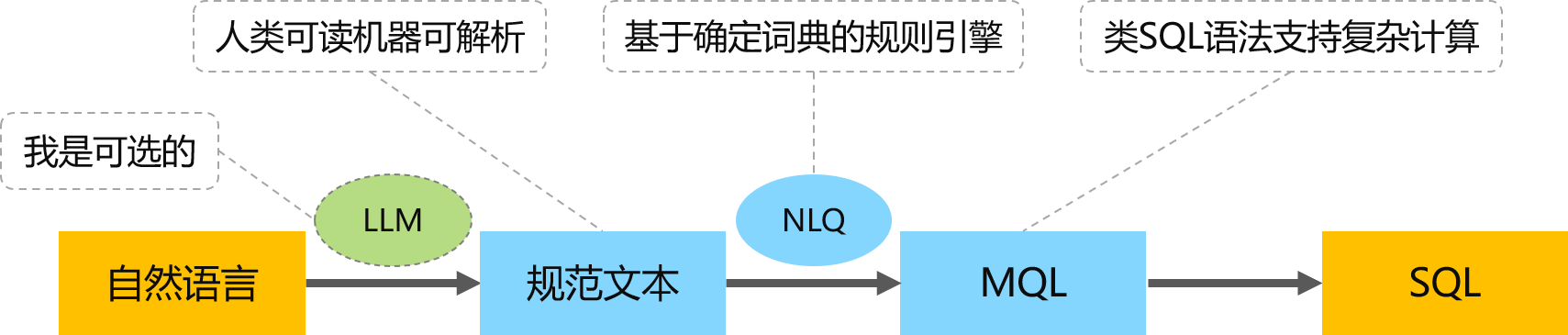
- 规范文本控幻:自然语言人类可读可确认
- NLQ确定转换:解析规范文本准确转换MQL
- MQL复杂支持:支持关联嵌套等全BI场景
规范文本
规范文本:人机协同的“通信协议”
规范的自然语言
自然语言
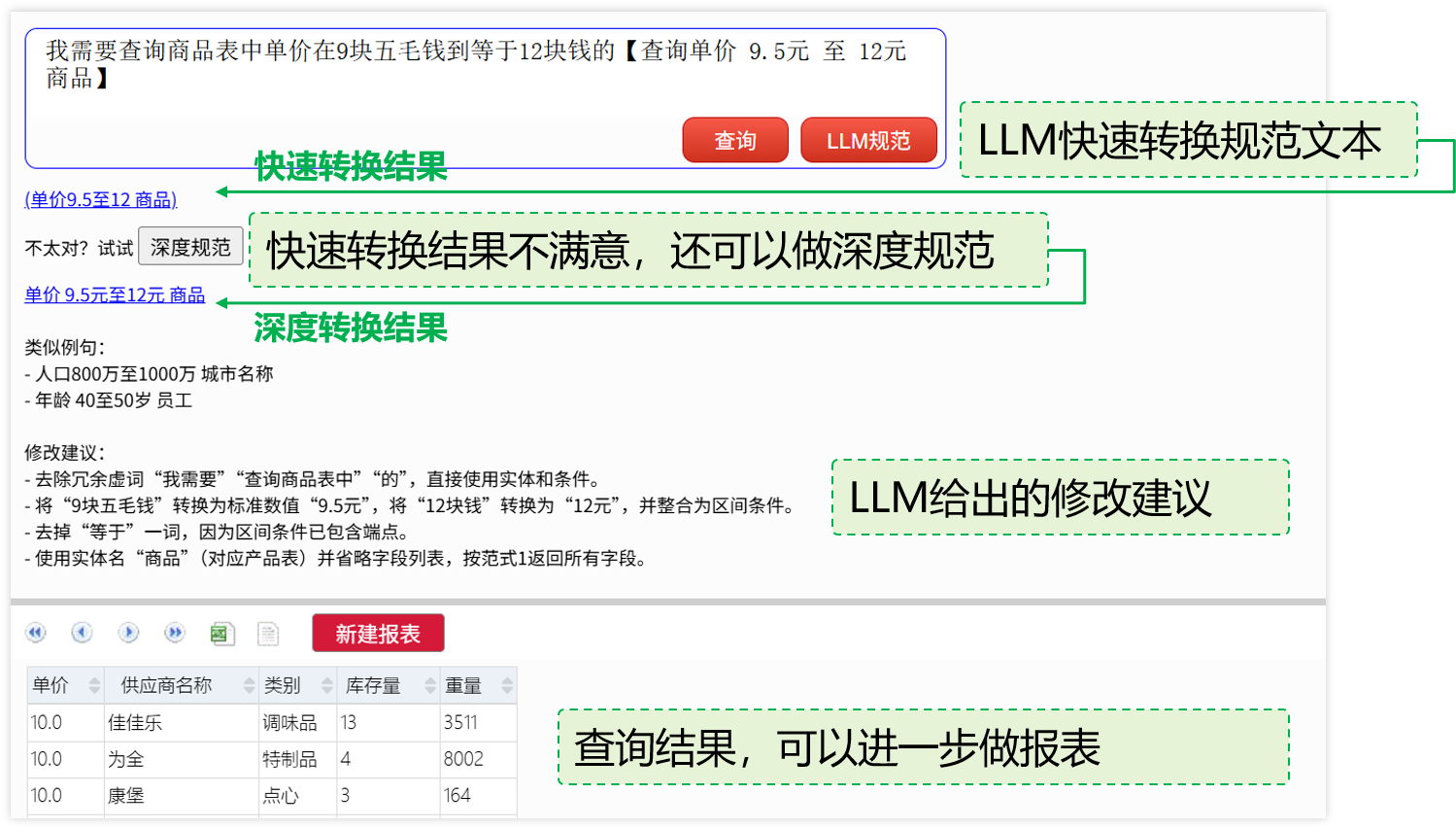
- 出生日期在 1986 年 1 月至 7 月的雇员(前后单位不统一,后面缺少年份)
- 请帮我查一下 2023 年北京发往青岛的订单(有“请帮我查一下”这类虚词)
- 查询商品表中单价在 9 块五毛钱到等于 12 块钱的(查询条件描述过于口语化)
规范文本
- 出生日期在 1986 年 1 月至 1986 年 7 月的雇员
- 2023 年北京发往青岛的订单
- 商品单价大于等于 9.5 小于等于 12
LLM转换成规范文本也会有幻觉,但你能看出来转的对不对
人机双向可读
人类可确认性

规范文本采用业务人员熟悉的自然语言,使用户能够直观确认查询意图,确认环节是解决幻觉问题的关键
机器可解析性

规范文本遵循预定义的结构与词汇表,具备极强的机器可解析性,为支撑复杂查询奠定了基础
规范文本的意义
- 角色重塑LLM任务简化为文本转写,通用模型即可工作
- 准确稳定人类可确认与引擎校验构成双重保障,确保查询意图精准无误
- 破解困境兼顾自然语言的灵活性、规则引擎的准确性与企业级查询的复杂性
- 部署灵活规范文本可脱离LLM由直接工作,适应API方案运行
NLQ词典
NLQ引擎
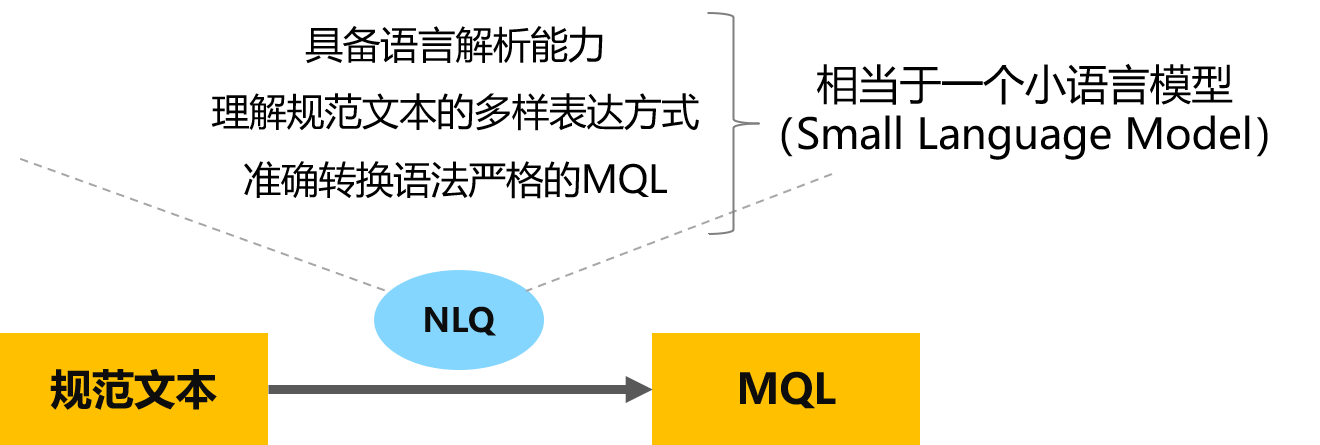
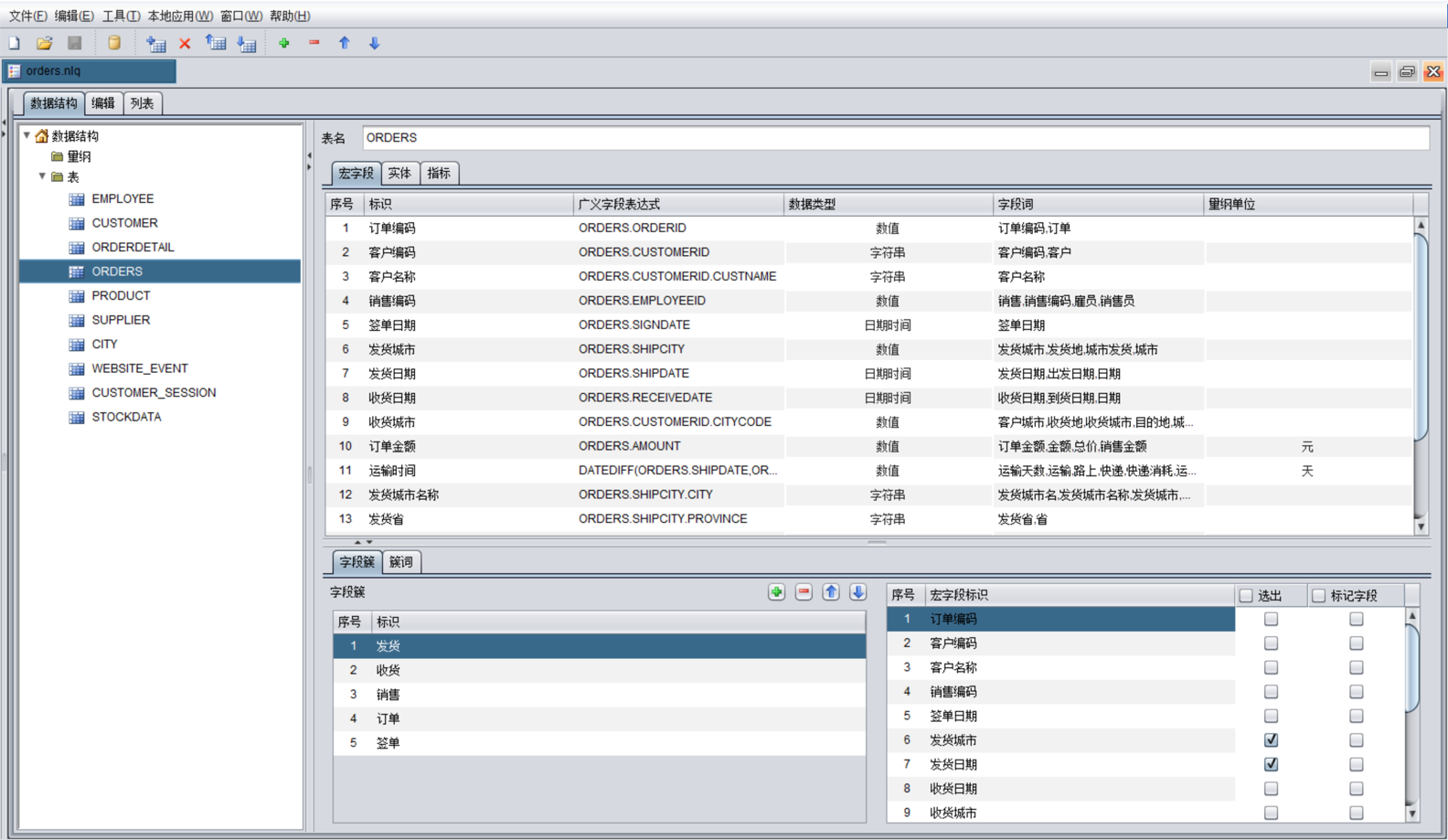
实现方式:NLQ词典
基于词典的规则引擎保证准确性
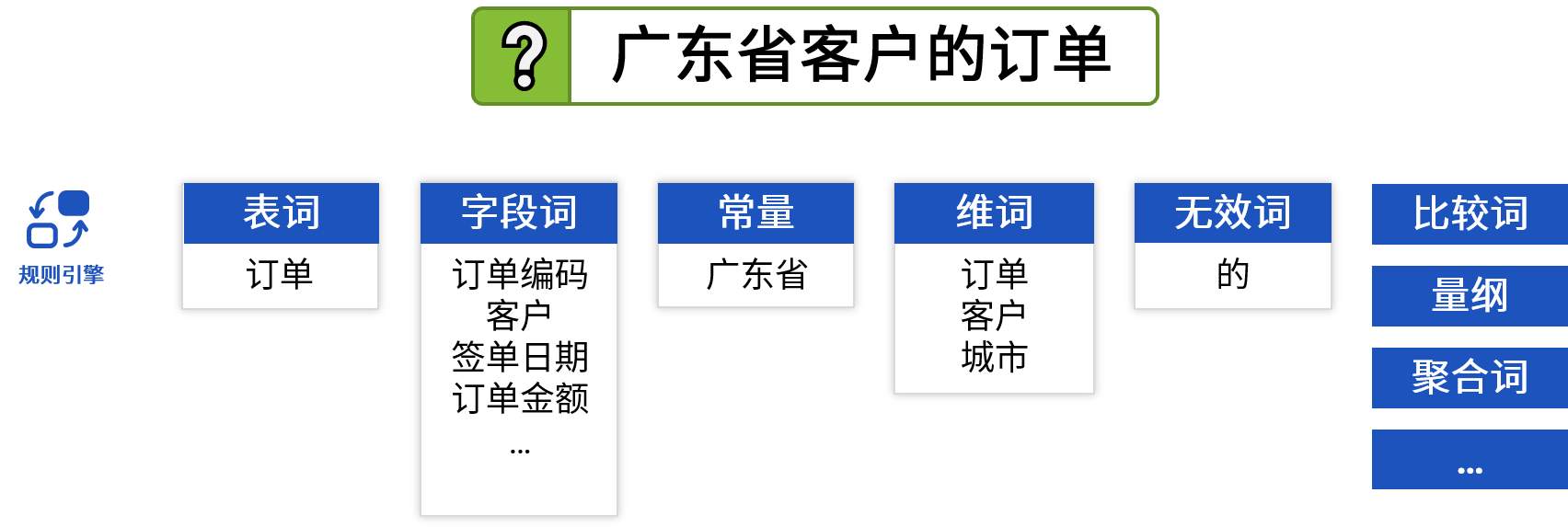
- 预先建立词典,导入数据结构,定义表词、字段词、维词等
- 利用词典解析出规范文本中的表、字段、比较符号、聚合函数等SQL要素
NLQ词典 – 基本概念
| 类别 | 说明 | 解释与示例 |
|---|---|---|
| 表与实体 |
表是数据库中的物理表。 实体是表的业务化视图,可定义不同的字段和过滤条件 |
• 示例:物理表销售订单可以定义两个实体: - “全部订单”:包含所有字段 - “本年新订单”:仅包含Year(签单日期)=Year(Now())的订单,并只显示订单ID、金额等核心字段 |
| 宏字段 | 查询的最小语义单元,是基础字段的扩展 |
• 基础字段:直接映射到表字段,如“订单金额” • 计算字段:通过表达式定义,如BMI指数 = (体重(kg) / 身高(m)²) • 外键字段:通过关联引入其他表信息,如通过“客户ID”引入“客户名称” |
| 指标 | 通过表达式定义的聚合度量,用于统计分析 |
• 简单指标:如“销售总额”(SUM)。 • 复杂指标(SPL):处理SQL不擅长的计算,如“用户留存率”、“股票连涨天数” |
| 字段簇与簇词 |
字段簇是一组业务紧密相关的字段集合 簇词是字段簇的业务别名,用于消除歧义 |
• 示例:定义“发货”簇(含城市、日期)和“收货”簇(含城市、日期)。 • 应用:用户说“发货 日期”,引擎能精准定位到“发货日期”,而不会与“签单日期”混淆 |
| 维、维词与常数词 | 维是分析视角,维词是其业务名,常数词将业务值映射到底层编码 |
• 示例:将“北京”、“上海”定义为“城市”维的常数词,映射到内部编码(30101, 30102) • 应用:用户查询“籍贯 北京 的雇员”,引擎自动转换为HOMECITY=30101 |
NLQ词典 – 特色词型
| 类别 | 说明 | 解释与示例 |
|---|---|---|
| 无效词 | 过滤掉查询中的口语化虚词和语气词,使引擎聚焦于有效信息 |
• 示例:“请帮我查一下”、“有哪些”、“那个”。 • 应用:用户输入“请帮我查一下有哪些销售额高的商品”,引擎会忽略加粗部分,直接解析核心意图 |
| 宏词 | 将口语化的业务概念转换为规范的查询过滤逻辑 |
• 示例:将“已售罄”定义为宏词,其背后逻辑是“库存量 <= 0” • 应用:用户查询“已售罄的商品”,引擎自动转换为库存量 <= 0 |
| 动词 | 用于建立复杂的过滤逻辑,特别是关联多个字段簇 |
• 示例:定义动词“发往”,将其左侧关联到“发货”簇,右侧关联到“收货”簇。 • 应用:用户查询“北京 发往 青岛 的订单”,被解析为发货城市=北京 AND 收货城市=青岛。 |
| 量词 | 用于处理带单位的数值,自动进行单位换算 |
• 示例:定义量词“万元”,换算系数为10000。 • 应用:用户查询“金额大于 20万元”,引擎会自动转换为金额 > 20*10000 |
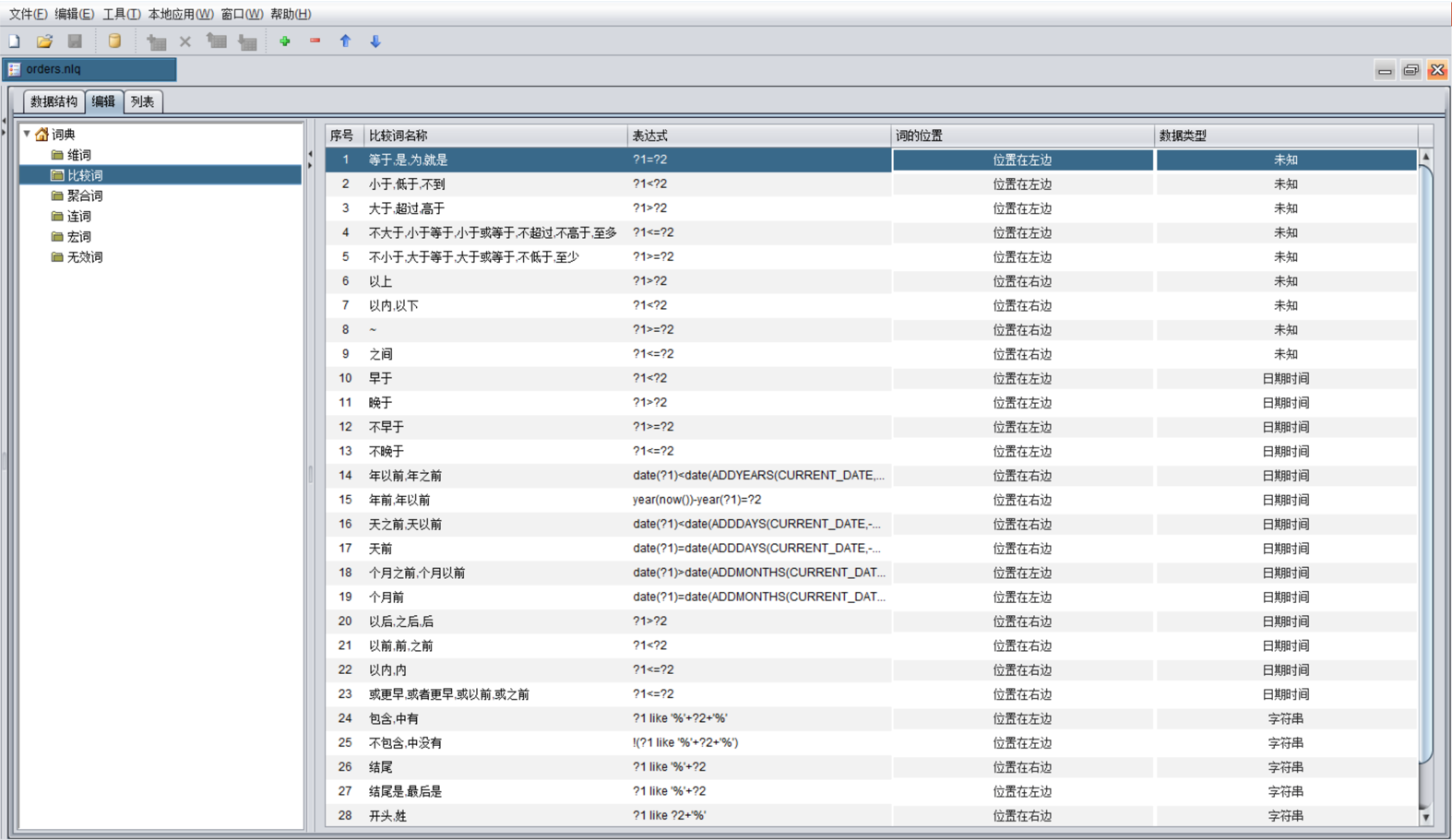
| 比较词与连词 | 定义过滤关系与条件间的逻辑连接 |
• 比较词:大于、小于、等于。 • 连词:且、或。 • 应用:支持“年龄大于 40 且 性别 等于 男”这样的复杂条件组合 |
实例解析
1基础过滤查询
姓名为李芳的职务、出生日期和年龄
NLQ 引擎解析:
- 分词:姓名,李芳,职务,出生日期,年龄
- 识别:“姓名”、“职务”、“出生日期”、“年龄”被识别为字段词,确定它们来自员工实体
- “李芳”被识别为常数,由于前一个词是字段词“姓名”,引擎将其构建为过滤条件姓名 ='李芳'
- 生成 MQL:SELECT 姓名, 职务, 出生日期, 年龄 FROM EMPLOYEE WHERE 姓名 ='李芳'
SQL
SELECT T_1."NAME" "姓名", T_1."EMPID" "雇员编码", T_1."TITLE" "职务", T_1."BIRTHDATE" "出生日期", (YEAR(NOW)-YEAR(T_1."BIRTHDATE")- CASE WHEN MONTH(NOW)* 100 + DAY(NOW)>MONTH(T_1."BIRTHDATE")* 100 + DAY(T_1."BIRTHDATE") THEN 0 ELSE 1 END ) "年龄" FROM EMPLOYEE T_1 WHERE (T_1."EMPID" = 3)
2字段簇与动词消除歧义
北京发往青岛的订单
NLQ 引擎解析:
- 分词:北京,发往,青岛,订单
- 识别:“订单”被识别为实体
- “发往”被识别为动词簇词。查询动词定义,知其关联“发货”和“收货”两个字段簇
- “北京”在动词左侧,被分配给“发货”簇中的“城市”字段
- “青岛”在动词右侧,被分配给“收货”簇中的“城市”字段
- 生成 MQL:SELECT ... FROM ORDERS WHERE (发货城市 =30101) AND (收货城市 =20201)(其中代码由常数词映射而来)
SQL
SELECT T_1_1."SHIPCITY" "发货城市", T_1_2."CITYCODE" "客户城市", T_1_1."ORDERID" "订单编码", T_1_1."SIGNDATE" "签单日期", T_1_1."SHIPDATE" "发货日期", T_1_1."RECEIVEDATE" "收货日期", T_1_1."AMOUNT" "订单金额" FROM ORDERS T_1_1 LEFT JOIN CUSTOMER T_1_2 ON T_1_1."CUSTOMERID" = T_1_2."CUSTID" WHERE ((T_1_1."SHIPCITY" = 30101) AND(T_1_2."CITYCODE" = 20201))
3复杂聚合与子查询
订单金额总和大于 20 万元的女员工
NLQ 引擎解析:
- 识别主体“员工”为实体;“女”为常数词,与“性别”维匹配,过滤员工表
- “订单金额总和大于 20 万元”是一个聚合条件。识别出“订单金额”来自订单表,“总和”是聚合词,“大于 20 万元”是比较条件。由于订单表与员工表通过“销售”字段关联,引擎识别出这是一个基于子表聚合结果的过滤
- "大于 20 万元" 这个比较条件,NLQ 引擎会识别 "万元" 为量词,并根据词典中定义的换算系数(1 万元 =10000)自动进行单位转换。"20 万元" 在生成 MQL 时将被转换为 20*10000,而不是直接使用数值 200000,体现了量词保持业务表达的自然性
- 生成 MQL,此 MQL 会表达从员工表中查询,其条件为子表(订单表)中对应销售员的订单金额总和大于 200000
- 生成 MQL:
SELECT 性别 ,…,ORDERS.sum(订单金额) AS 订单金额总和 FROM EMPLOYEE WHERE (性别 ='女') JOIN ORDERS HAVING 订单金额总和 >20*10000
SQL
SELECT T_1."EMPID" "雇员编码", T_1."GENDER" "性别", T_1."NAME" "姓名", T_1."TITLE" "职务", T_1."BIRTHDATE" "出生日期", (YEAR(NOW)-YEAR(T_1."BIRTHDATE")- CASE WHEN MONTH(NOW)* 100 + DAY(NOW)>MONTH(T_1."BIRTHDATE")* 100 + DAY(T_1."BIRTHDATE") THEN 0 ELSE 1 END ) "年龄", T_2.F_2 "订单金额总和" FROM EMPLOYEE T_1 LEFT JOIN ( SELECT T_2."EMPLOYEEID" F_1,sum(T_2."AMOUNT") F_2 FROM ORDERS T_2 GROUP BY T_2."EMPLOYEEID") T_2 ON T_1."EMPID" = T_2.F_1 WHERE ((T_2.F_2>20)) AND ((T_1."GENDER" = '女'))
4多表汇总与复杂指标计算
各省的员工数、产品数和大订单数
NLQ 引擎解析:
- 识别 "各省" 为维词,作为统一的分组维度
- "员工数"、"产品数" 被识别为基于 EMPLOYEE 表和 PRODUCT 表的计数聚合
- "大订单数" 是一复杂指标,该指标采用 SPL 语法定义,用于计算订单金额超过最大订单金额 50% 的订单数量
- 引擎识别出这是一个多表同维汇总与复杂指标结合的查询,需要按照 "省份" 维度分别从员工表、产品表和订单表进行聚合计算,其中订单表需要调用 SPL 指标函数进行复杂计算
- 生成 MQL:此 MQL 会表达为按省份维度,分别统计员工数量、产品数量,并调用大订单数指标进行计算
- 生成 MQL:
SELECT EMPLOYEE.count(雇员编码) AS 员工数, PRODUCT.count(产品编码) AS 产品数, ORDERS. 大订单数 () AS 大订单数 ON 省份 FROM EMPLOYEE BY 省份 JOIN PRODUCT BY 省份 JOIN ORDERS BY 省份
指标定义(SPL语法):大订单数=(x=?1.max(订单金额)/2,?1.count(订单金额>=x))
SQL
SELECT COALESCE(T_1.F_1,T_2.F_1,T_3.F_1) "省",T_1.F_2 "员工数",T_2.F_2 "产品数",T_3.F_2 "订单数" FROM (SELECT T_1_2."PROVINCE" F_1, count(1) F_2 FROM EMPLOYEE T_1_1 LEFT JOIN CITY T_1_2 ON T_1_1."HOMECITY" = T_1_2."CITYCODE" GROUP BY T_1_2."PROVINCE") T_1 FULL JOIN ( SELECT T_2_3."PROVINCE" F_1, count(1) F_2 FROM PRODUCT T_2_1 LEFT JOIN SUPPLIER T_2_2 ON T_2_1."SUPPLIERID" = T_2_2."SUPPLIERID" LEFT JOIN CITY T_2_3 ON T_2_2."CITY" = T_2_3."CITYCODE" GROUP BY T_2_3."PROVINCE") T_2 ON T_1.F_1 = T_2.F_1 FULL JOIN ( SELECT T_3_2."PROVINCE" F_1, count(1) F_2 FROM ORDERS T_3_1 LEFT JOIN CITY T_3_2 ON T_3_1."SHIPCITY" = T_3_2."CITYCODE" GROUP BY T_3_2."PROVINCE") T_3 ON COALESCE(T_1.F_1,T_2.F_1)= T_3.F_1
NLQ引擎与LLM可解释性对比
| 对比维度 | NLQ | LLM |
|---|---|---|
| 核心逻辑 | 基于确定性规则,过程透明、稳定 | 基于概率的黑箱模型,内部逻辑不可知 |
| 调试与追溯 | 每一步可追溯、可解释,像程序调试一样定位问题 | 过程不可追溯,如同猜测一个“黑盒”为何出错 |
| 问题根源诊断 | 可快速精准定位:是缺少词条、配置不当,还是引擎BUG? | 难以诊断根源:是提示词问题、知识缺失,还是模型幻觉? |
| 优化与迭代 | 通过补充和修改词典配置即可修复,成本低,效果可预测 | 依赖大量成本进行再训练,效果难以预测和保证 |
| 可控性 | 高度可控,系统的行为由明确的规则定义和约束 | 缺乏可控性,生成结果不稳定,易出现意想不到的输出 |
NLQ词典-领域知识的完美容器
规则引擎精确查询
- 抽象汉语规律得到规则模型,建立词典
- 词典中的词对应查询要素,准确承载了领域知识
- 把自然语言匹配到词的过程,就是应用领域知识的过程
准确性优势
- 规则引擎的领域知识就像是“手册”中的明文规定, LLM的知识则是“模糊记忆”
- 比如“昨日存款总额”,规则引擎可明确定义公式,各币种折合成人民币再汇总
成本优势
- 词典规模不会查过十几万字符,规则引擎仅用普通CPU运算即可高效处理
- 规则引擎在普通笔记本电脑都能流畅运行,不需要高端GPU集群,成本很低
NLQ结果更适合业务人员
构建词典可视化IDE
MQL
MQL:精确语义的承载者
类SQL语法 · 精确的语义基准 · 可控的查询范围
四类查询范式
单表明细查询
单表汇总查询
多表明细查询
多表汇总查询
单表明细查询:基础数据筛选
订单金额不低于 1 千元的订单
SELECT 订单金额 as 订单金额,订单编码,客户名称,签单日期,发货日期,收货日期 FROM orders WHERE 订单金额>=1000
基于单一数据源且不涉及聚合计算:
- 字段精确映射:将“订单金额”、“客户名称”等自然语言词汇准确对应到数据库字段
- 条件准确转换:将“不低于 1 千元”转换为精确的数值比较条件订单金额 >=1000
- 结果集规范:明确指定需要返回的字段集合
单表聚合查询:维度聚合分析
各城市发货总金额
SELECT orders.sum(订单金额) as 总金额 ON city as 城市 FROM orders BY 发货城市
引入了维度和聚合的概念:
- 维度建模:通过 ON city as 城市明确定义分析维度
- 聚合计算:使用 sum(订单金额) 实现指标汇总
- 分组逻辑:BY 发货城市 指定了分组依据字段
多表明细查询:关联信息整合
订单数大于5的客户信息和总订单金额
SELECT
客户编码,客户名称,联系人,联系人职务,城市编码,
orders.count(DISTINCT 订单编码) AS 订单数,
orders.sum(订单金额) AS 总订单金额
FROM customer
JOIN orders
HAVING (订单数> 5)
处理复杂数据关系的能力:
- 多表关联:通过 JOIN orders 实现客户表与订单表的关联
- 混合查询:在主表明细基础上挂载子表聚合结果
- 自动关联:基于元数据自动推导 customer 与 orders 间的关联条件
- 结果集过滤:通过 HAVING 对结果集进行过滤
多表汇总查询:多项指标对齐
各个类别的订单总数和在线订单数
SELECT orderdetail.count(DISTINCT 订单编码) as 订单总数,
website_event.sum(在线订单()) as 汇总在线订单数
ON ProductType as 类别
FROM orderdetail
BY 产品类别
JOIN website_event
BY 产品分类
更复杂的指标查询范式:
- 多源整合:从 orderdetail 和 website_event 两个独立数据源分别计算指标
- 维度对齐:通过 ON ProductType 实现不同来源数据按统一维度对齐
- 复杂指标:在线订单() 代表可预定义的业务指标计算
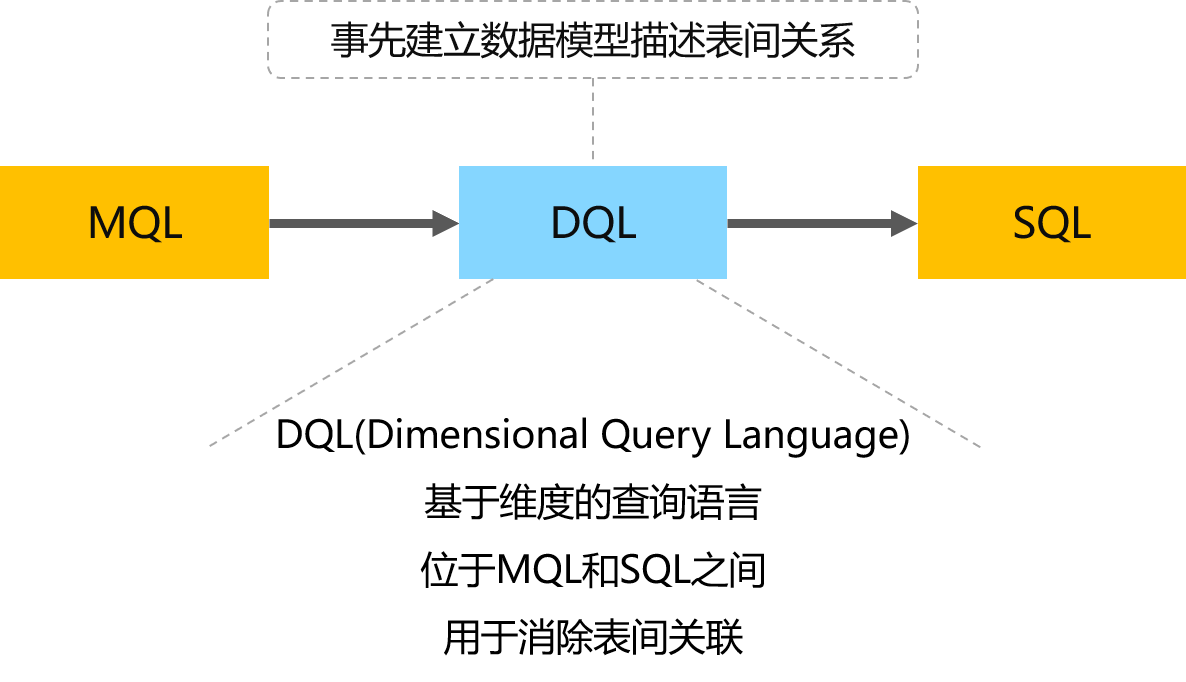
DQL:透明化表间关联
MQL并没有处理业务常见的多对一外键关联,这种情况如何处理?
用户输入
请查询北京发往青岛的订单
LLM转换规范文本:
北京 发往 青岛 订单
NLQ引擎生成MQL:
SELECT 发货城市,收货城市,订单编码,客户名称,签单日期,发货日期,收货日期,订单金额 FROM orders WHERE (发货城市=30101) AND (收货城市=20201)
进一步转换成DQL:
SELECT shipcity, customerid.citycode,orderid,customerid,signdate,shipdate,receivedate,amount FROM orders WHERE shipcity=30101 and customerid.citycode=20201
对象形式表达
DQL引擎生成SQL:
SELECT o.shipcity, c.citycode, o.orderid, o.customerid, o.signdate, o.shipdate, o.receivedate FROM orders o JOIN customer c ON o.customerid = c.id WHERE o.shipcity = 30101 AND c.citycode = 20201
显式关联

SPL:复杂指标计算
DQL的能力与SQL相当,BI中的复杂计算场景会存在局限,如何应对?
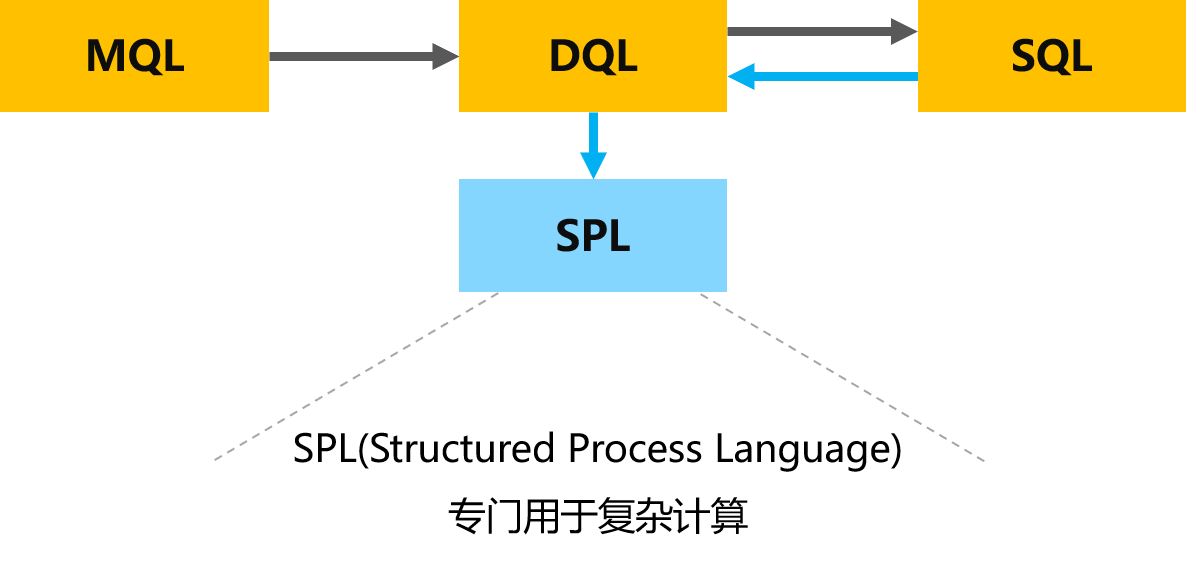
SPL擅长处理各类复杂计算场景
- 时序计算:支持移动平均、周期对比、连续增长等复杂时间序列分析
- 集合运算:处理分组排名、TopN 分析、集合交并差等操作
- 流程计算:实现漏斗分析、路径挖掘、归因分析等业务场景
- 数学计算:提供统计分布、相关性分析等高级功能
定义大订单(订单金额超过最大金额 50% 的订单)指标:
大订单=(x=?1.max(订单金额)/2,?1.count(订单金额>=x))
MQL直接使用:SELECT 大订单() , … FROM orders WHERE …
SPL-DQL计算引擎,性能超越关系数据库
关系数据库
- DQL转换成SQL可以提交关系数据库执行
- 数据量大关联复杂时会遇到性能问题,很难优化
SPL-DQL引擎
- DQL提交给SPL-DQL引擎执行是高性能之选
- 高性能二进制文件存储,支持列存、压缩、分段
- 多种高性能算法:有序关联、外键预关联/序号关联等
NLQ集成结构
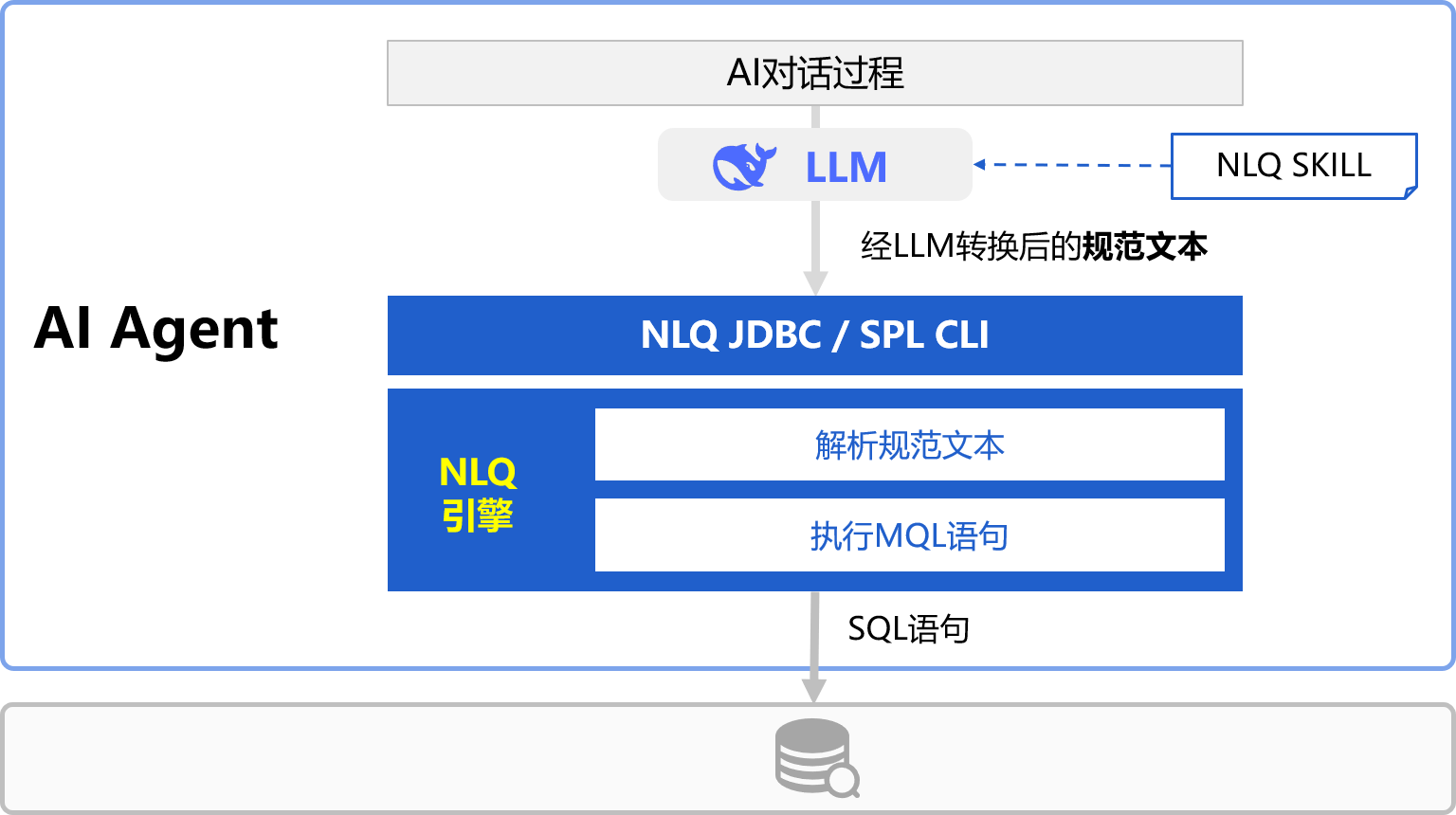
润乾全链AI+BI解决方案
NLQ Text2SQL
NLR Text2Report
润乾NLR是什么?
- 独创的Text2Report技术
- 查询结果用自然语言生成报表
- 全链AI+BI的第二个环节
NLR: Natural Language Report
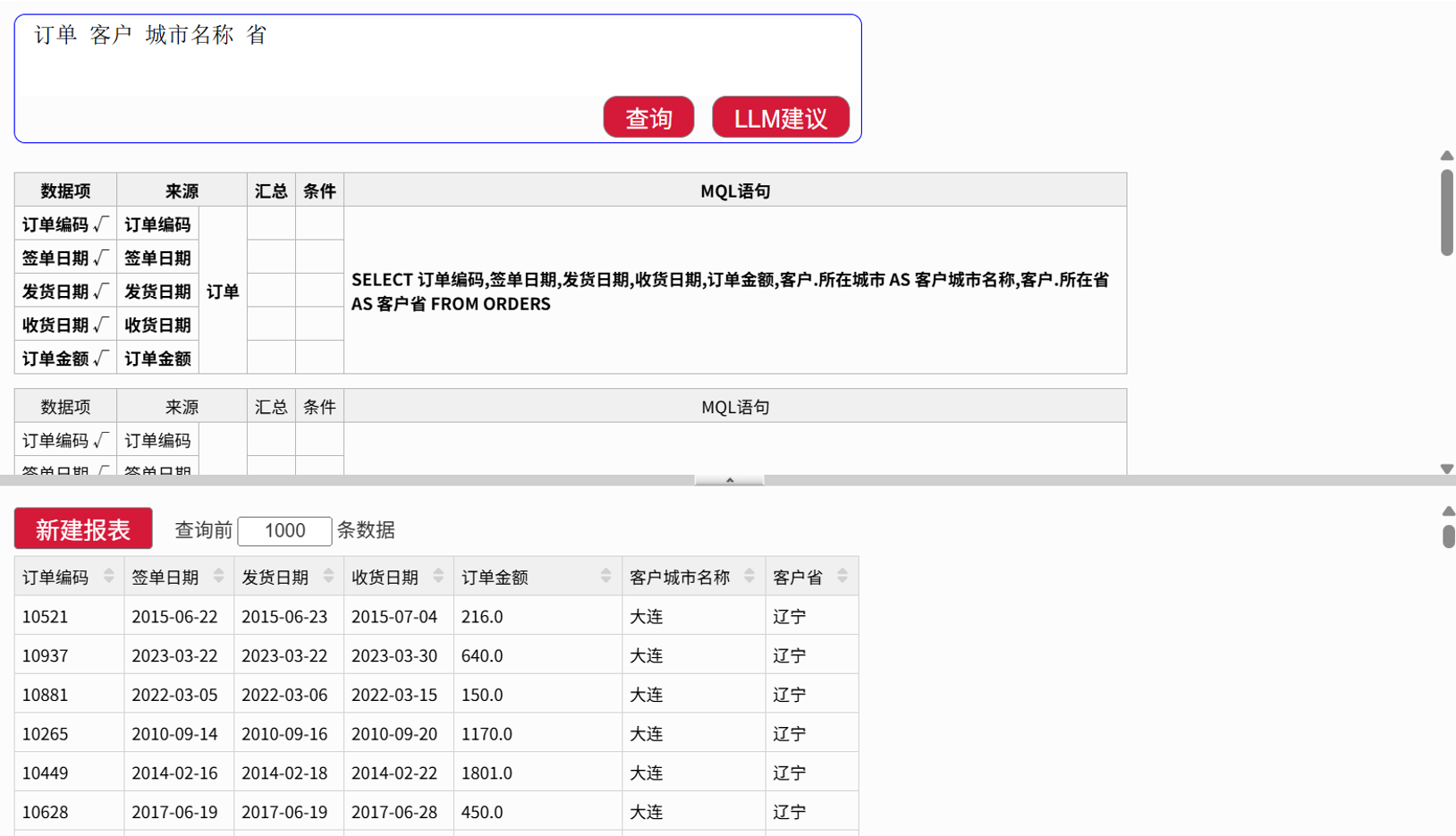
查询结果再制作报表
汉语查询结果,直接进行汉语报表(分组汇总)
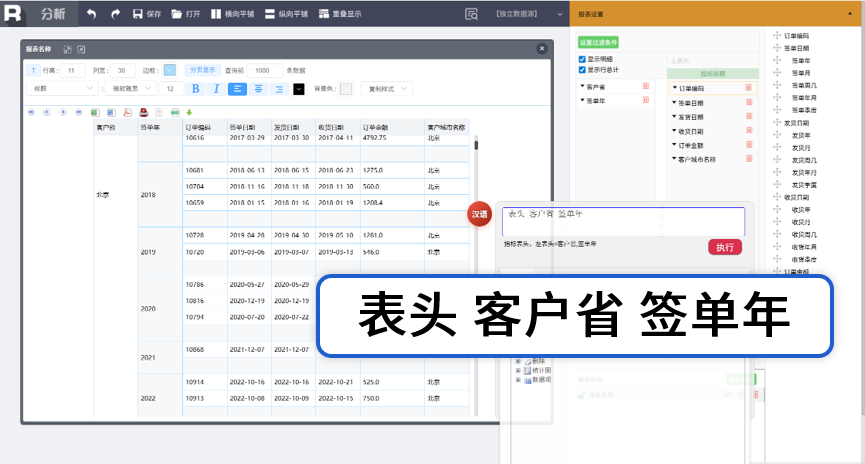
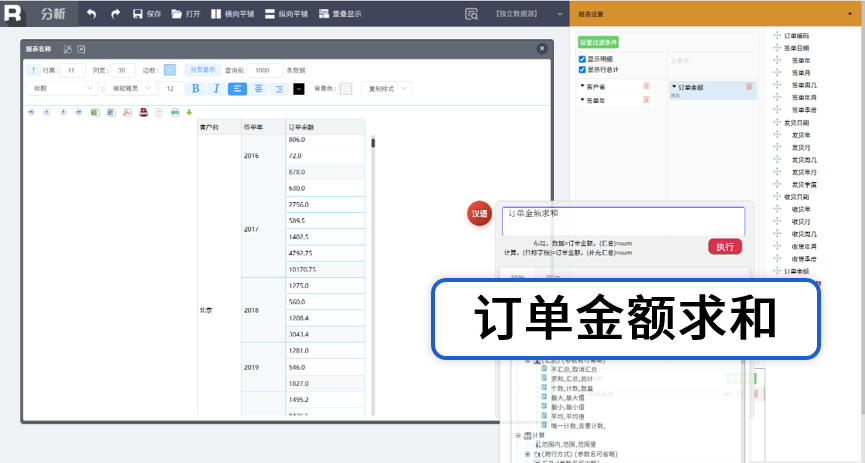
排名
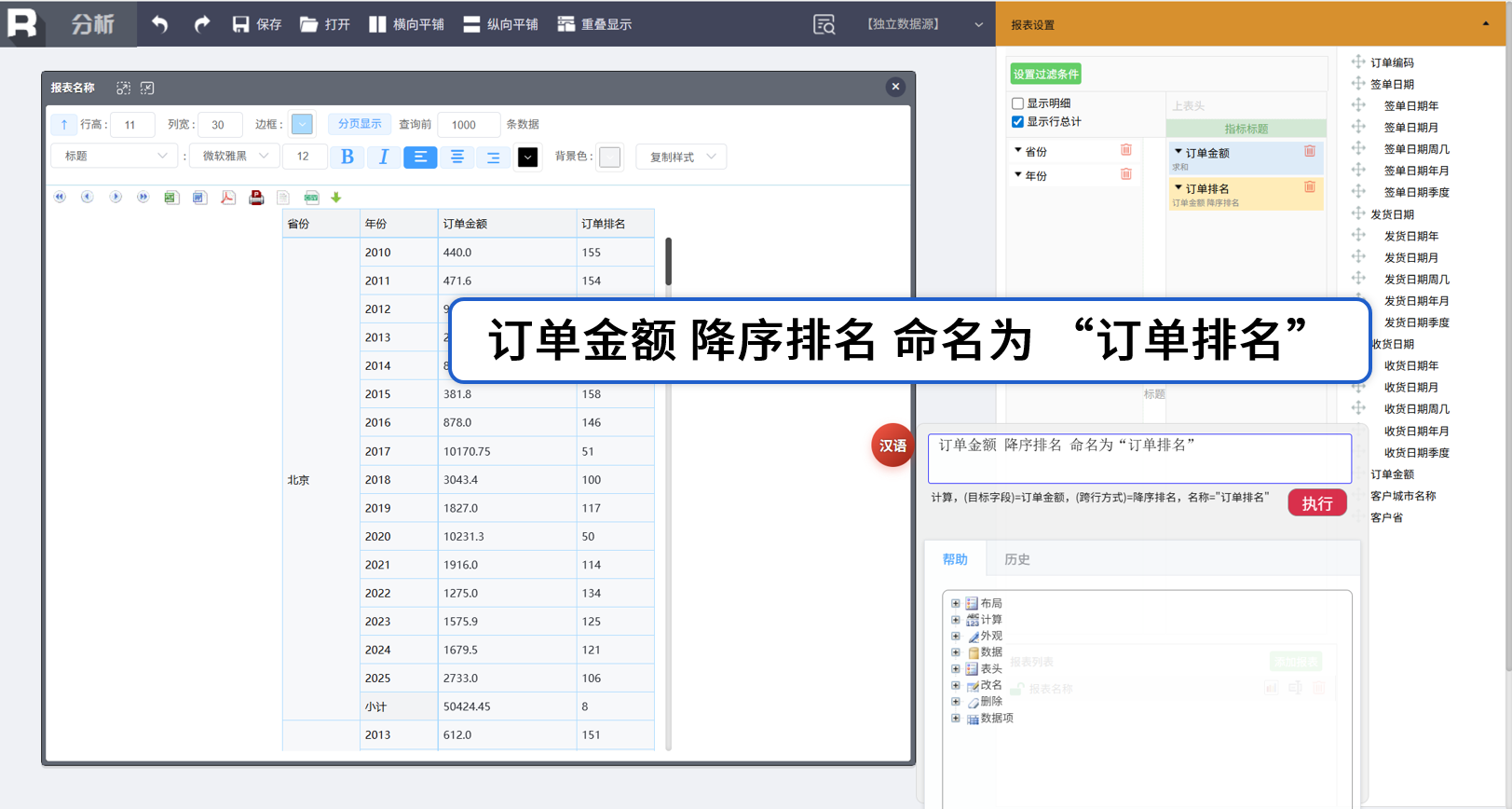
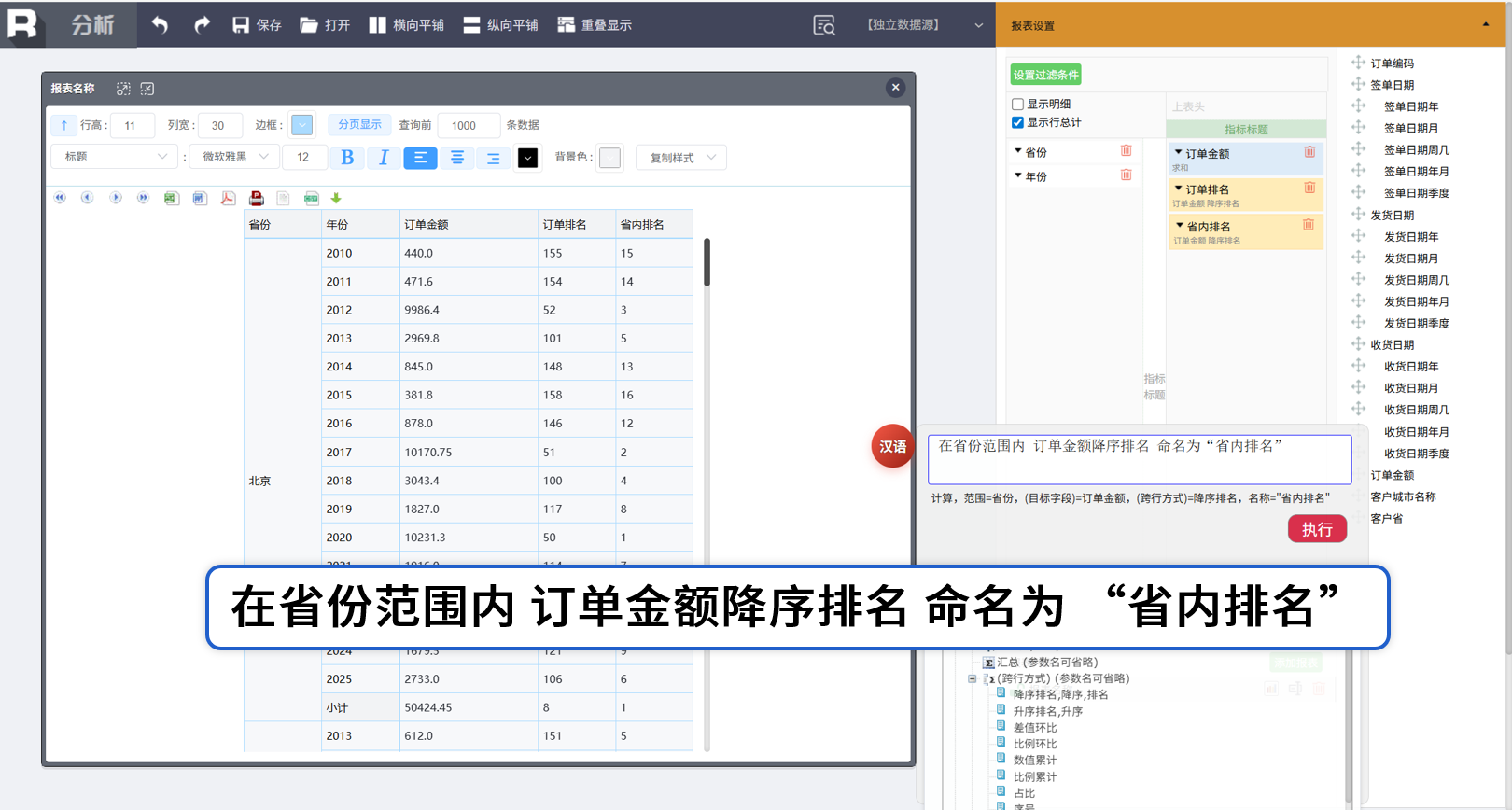
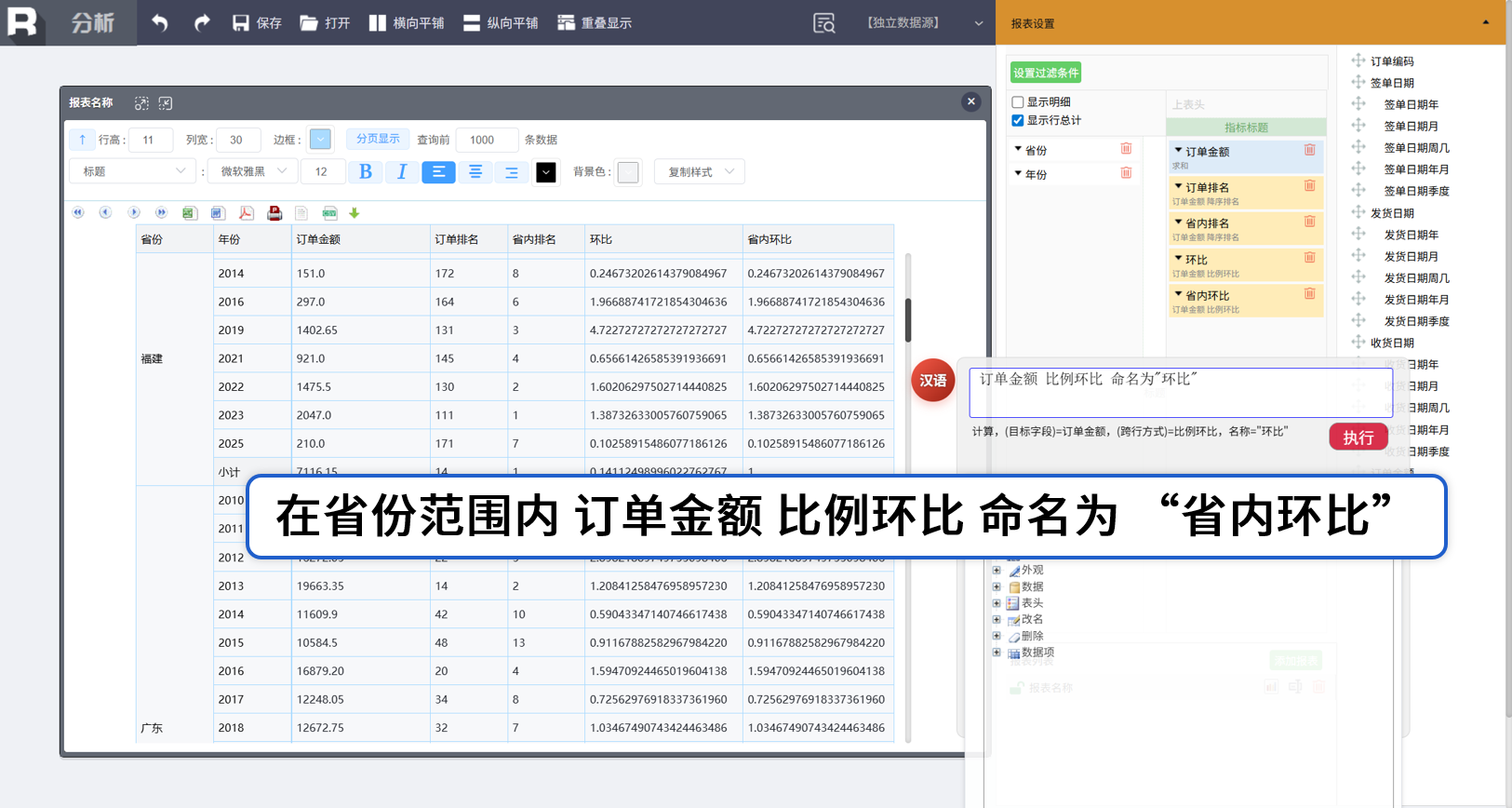
组内排名
环比
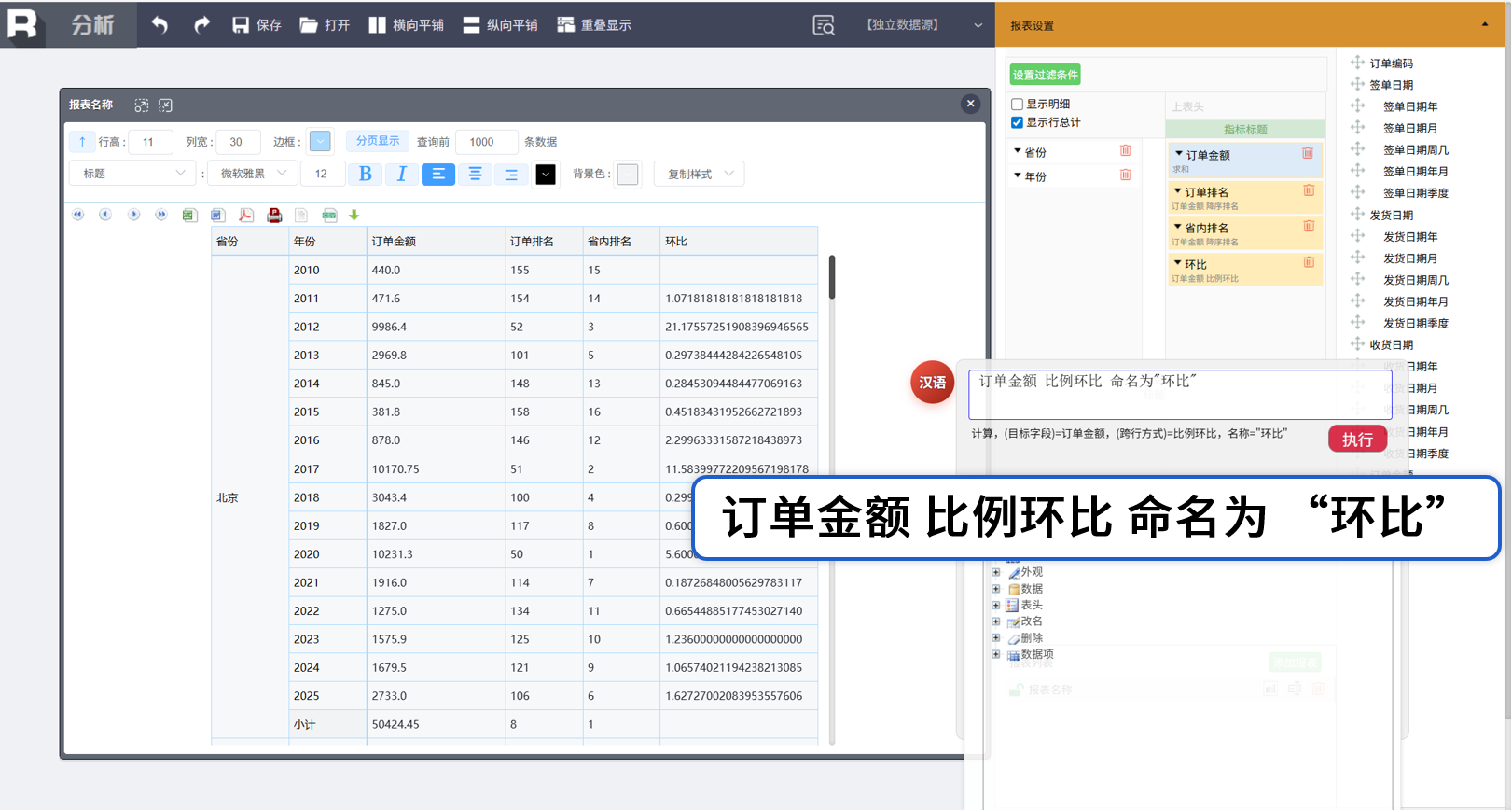
组内环比
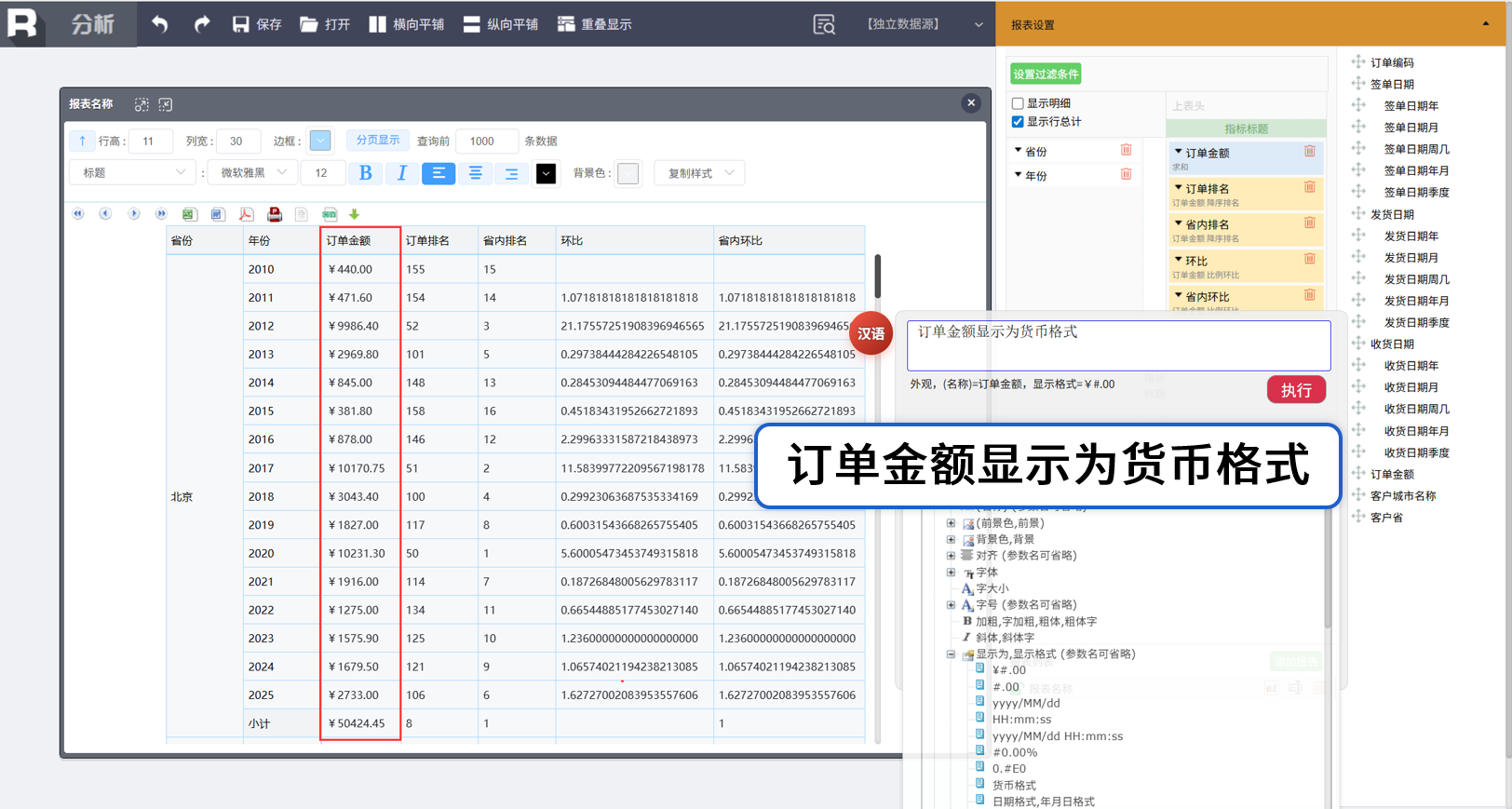
外观控制-显示格式
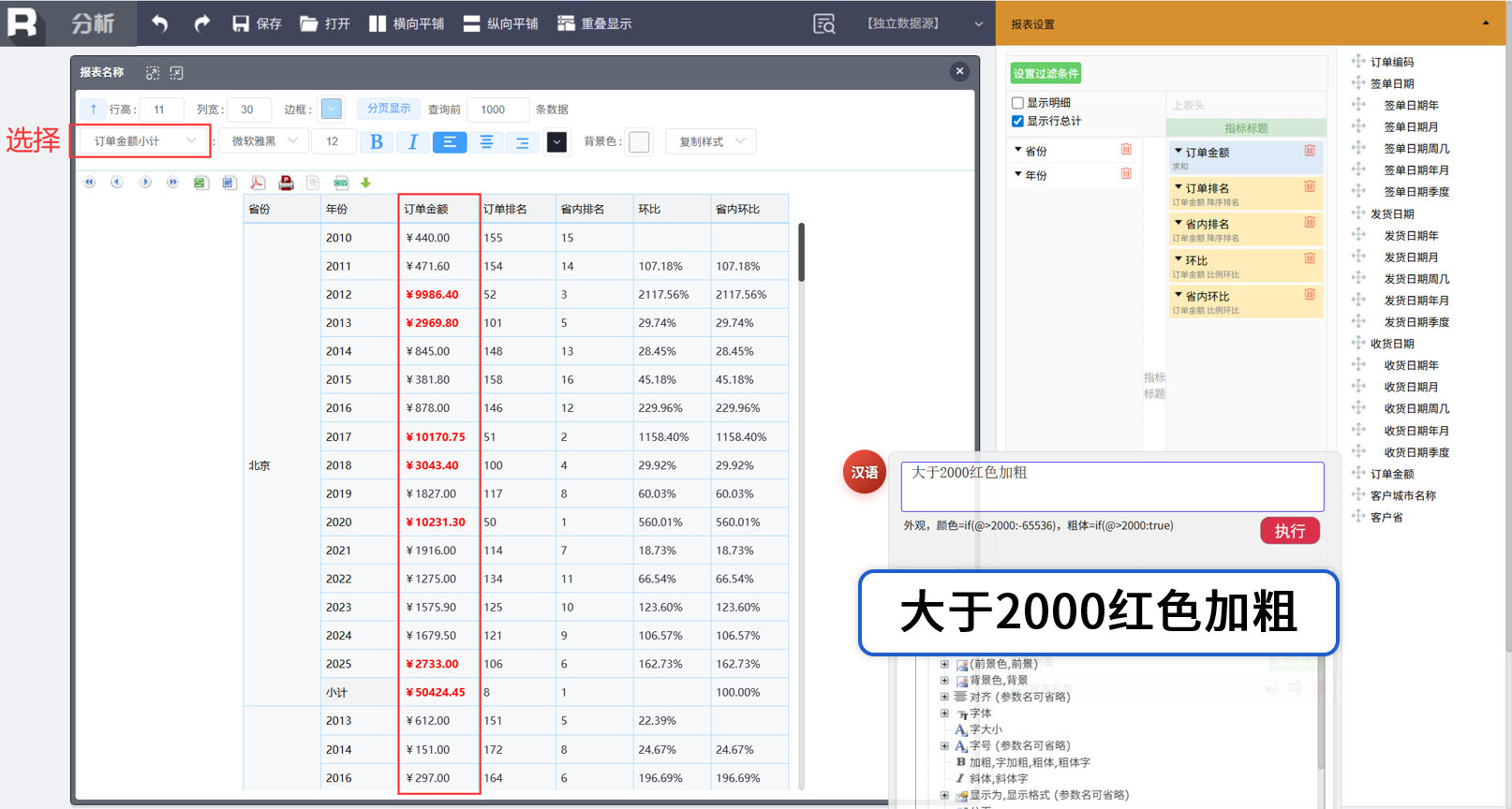
外观控制-条件控制
数据过滤(切片切块)
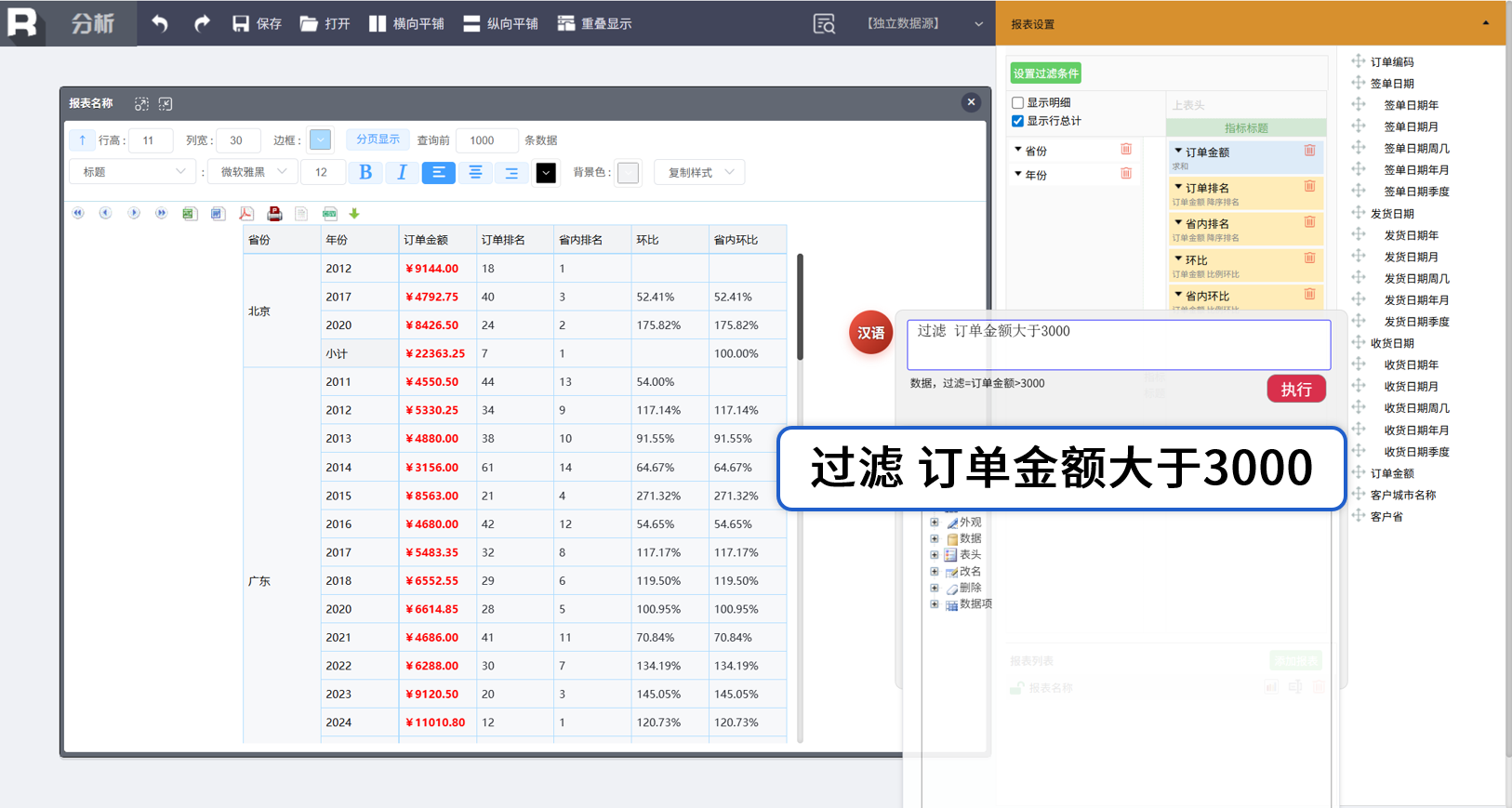
排序
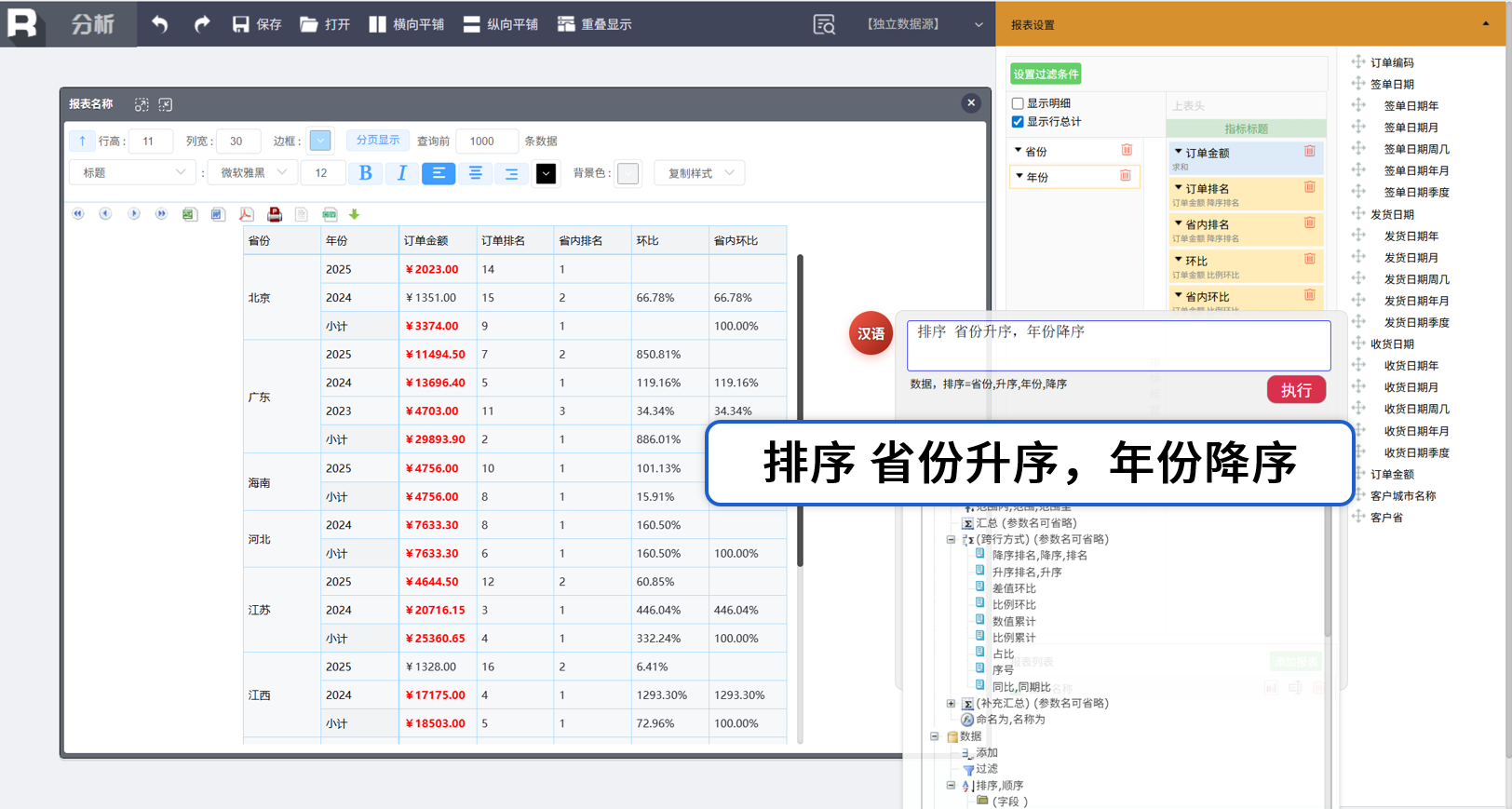
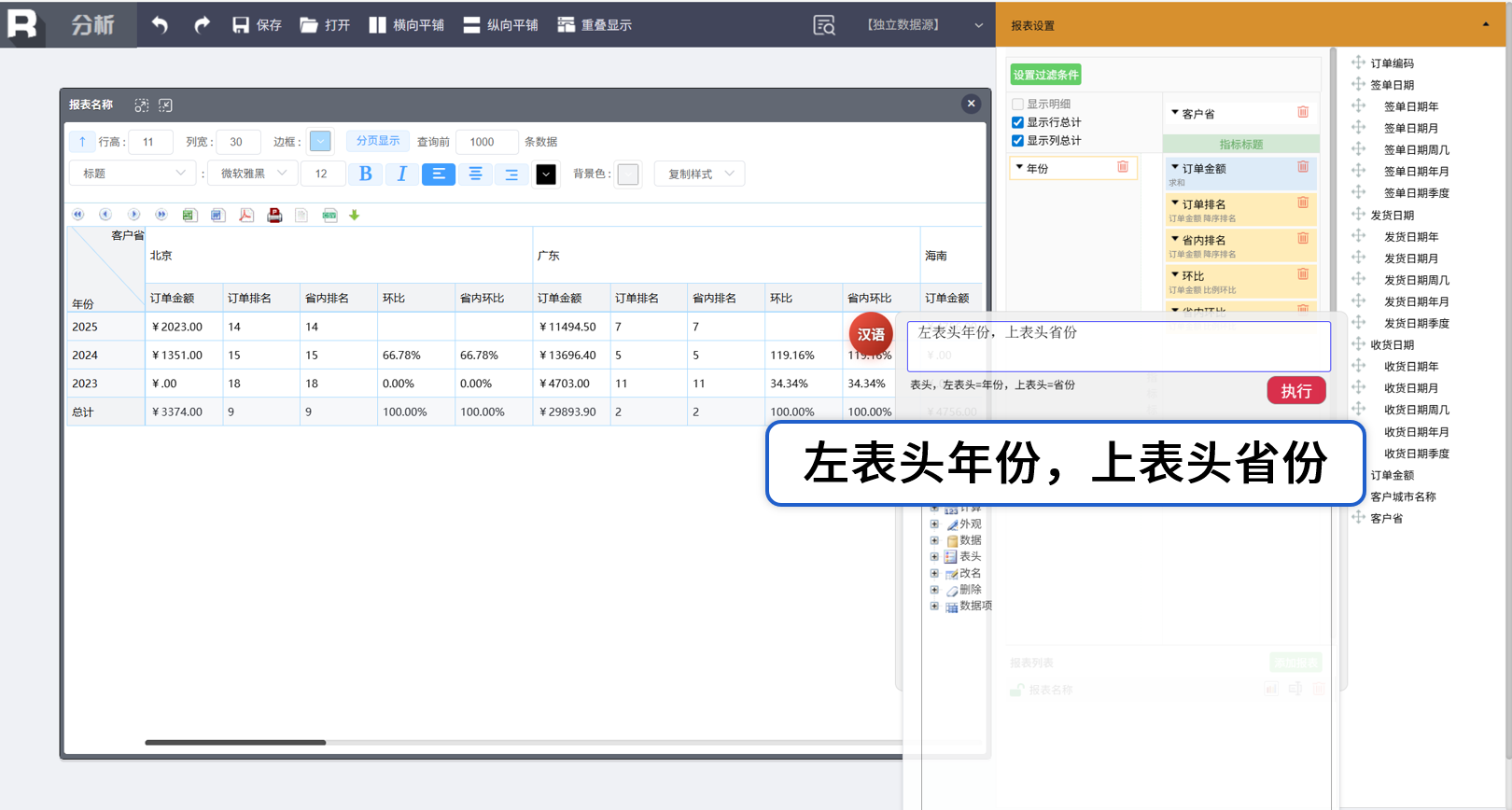
行列转换
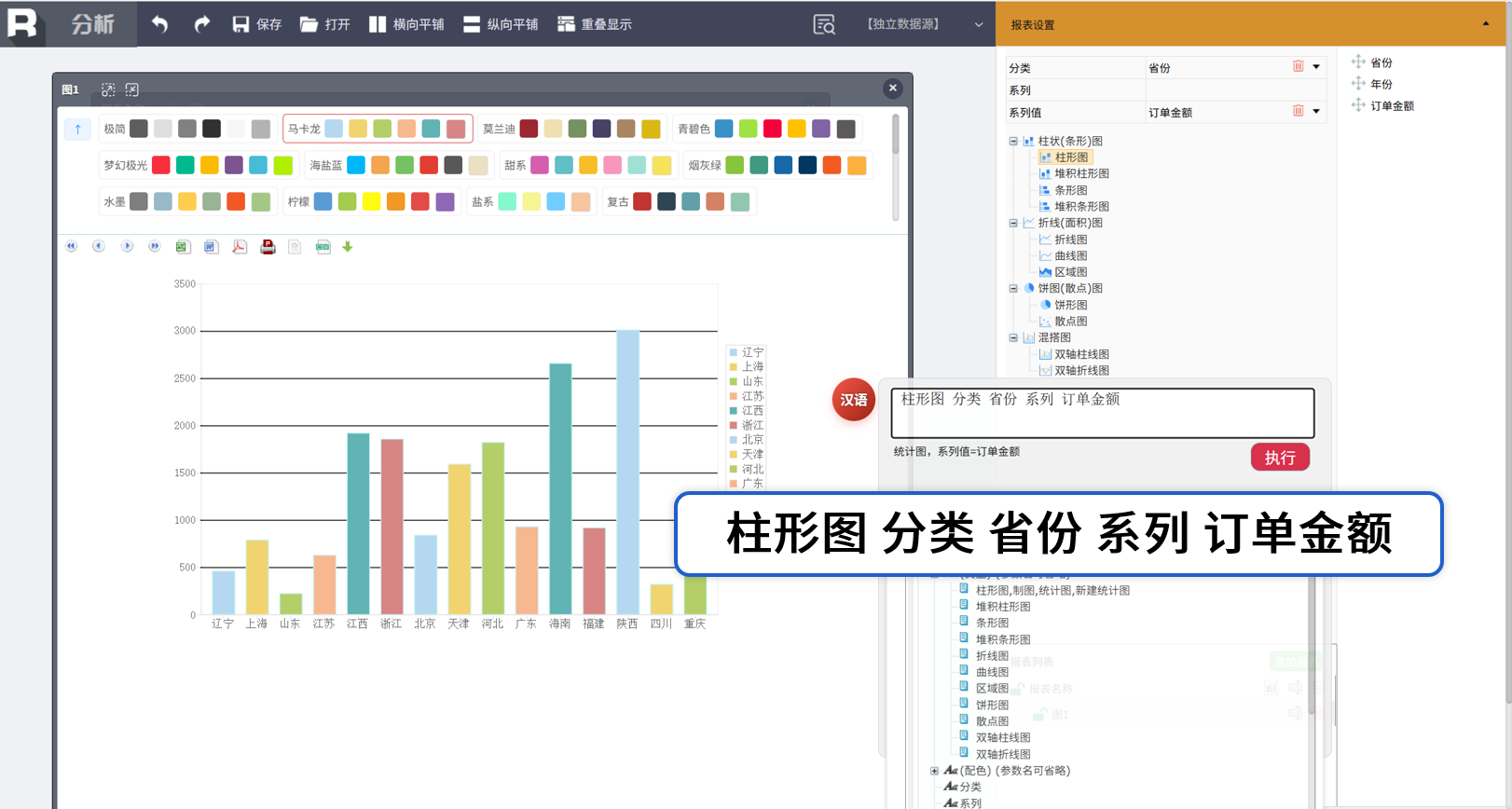
统计图绘制
更改统计图类型
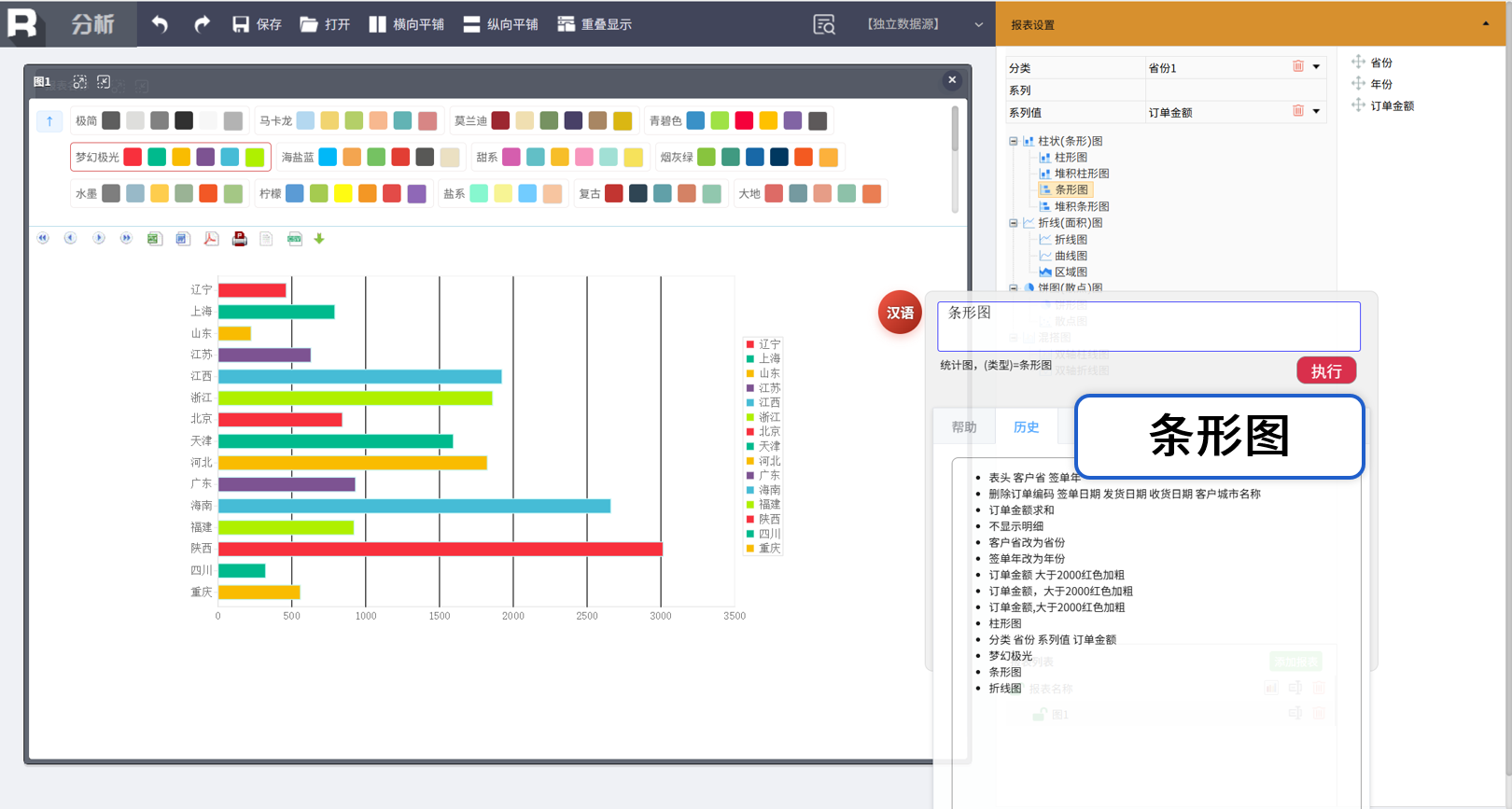
LLM规范-口语化命令
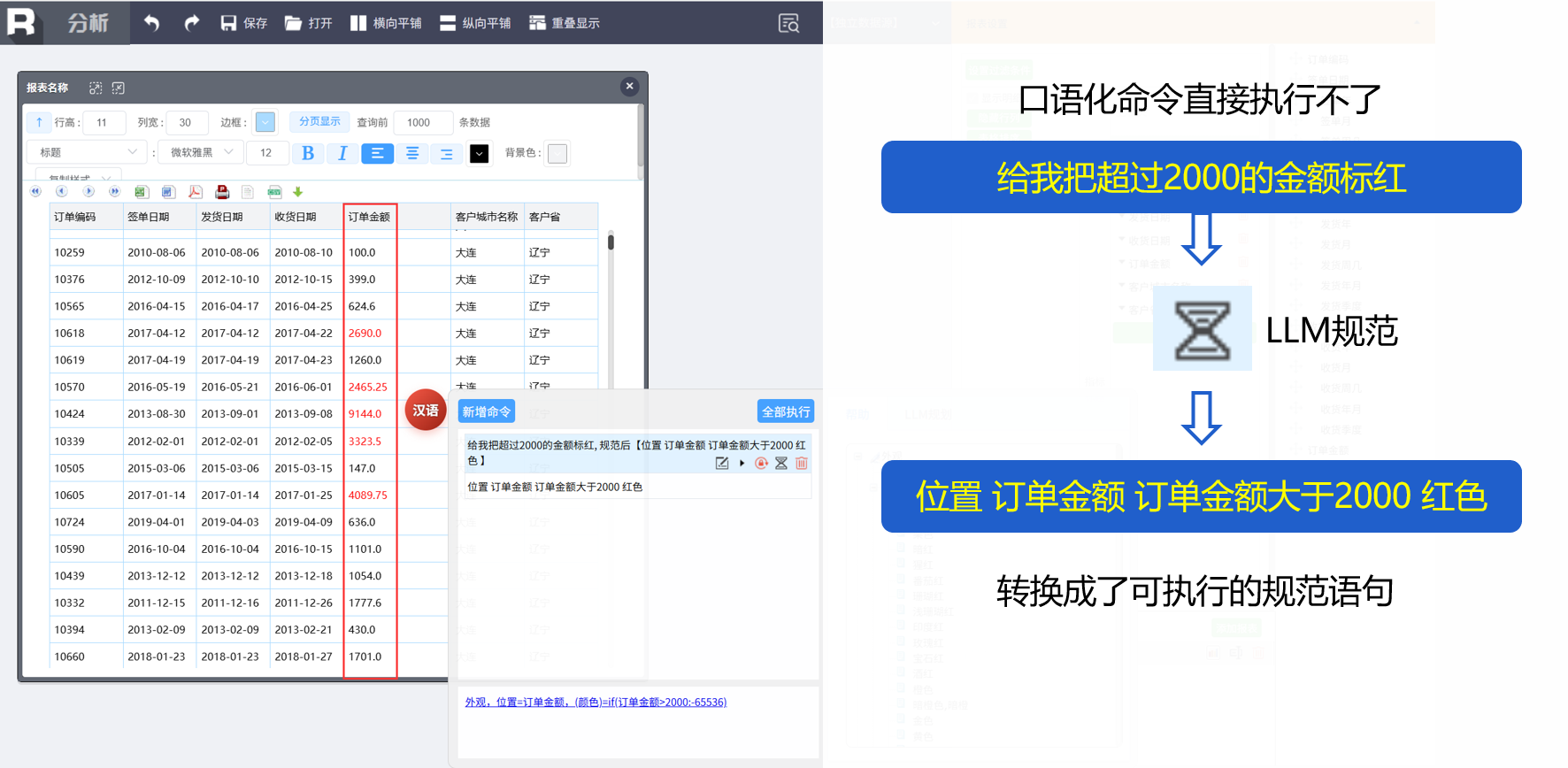
智能规划一次到位
借助LLM将制表任务(口语化)拆分成多个命令,全部或分步执行
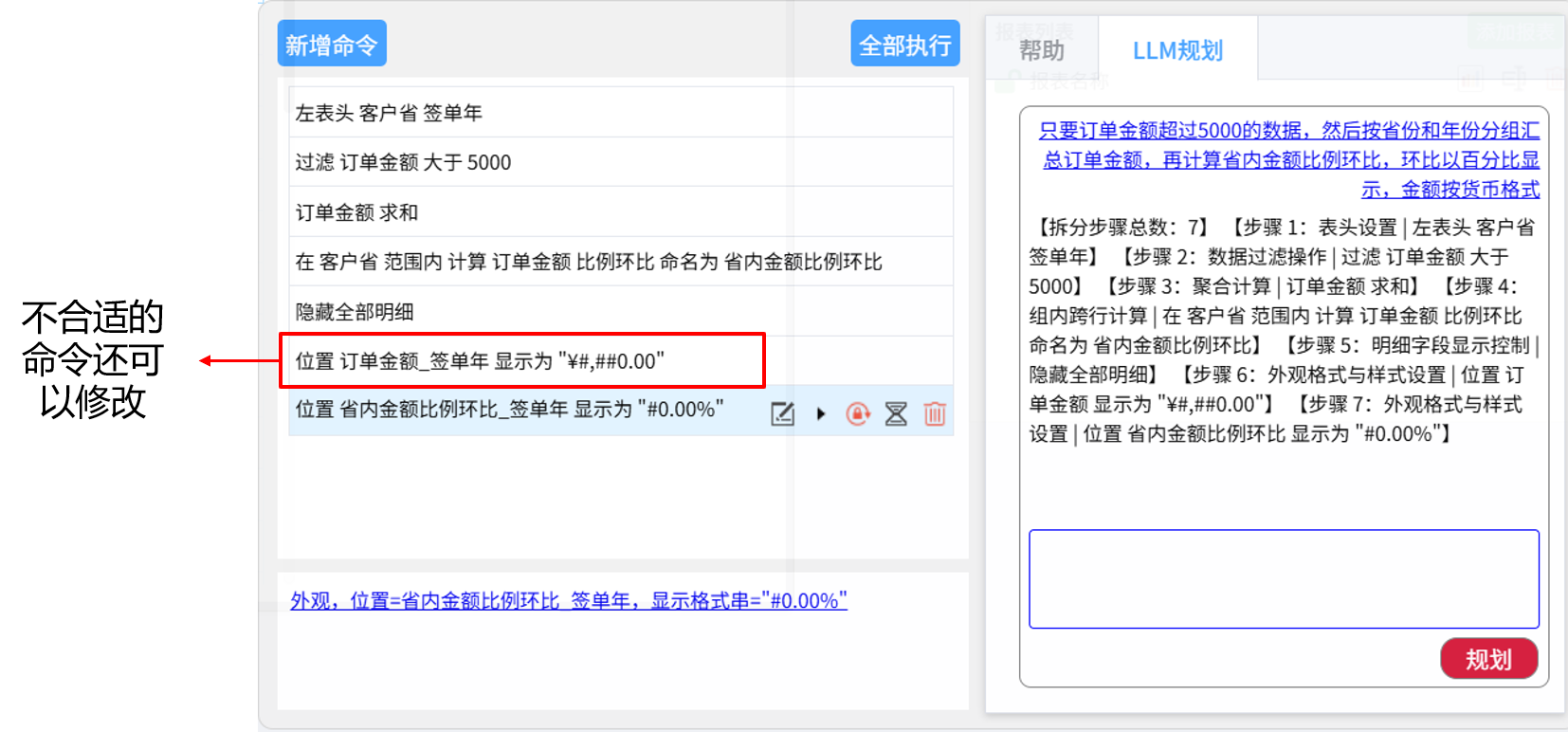
润乾全链AI+BI优势总结
灵活性
可选LLM保持灵活多样语言输入
幻觉可控
规范文本人类可读可确认
准确性
基于词典的NLQ引擎转换准确
复杂性
MQL-DQL-SPL支持复杂查询
高性能
高性能算法突破数据库性能瓶颈
低成本
无需GPU普通CPU环境即可部署
全链条
完整BI链条,自然语言闭环
指令确定
指令确定执行,过程可靠
操作直观
操作直观降低使用门槛