2.3.3排列是对序表记录的引用
如果针对序表的计算每次都生成新的序表,显然会占用大量的内存。比如序表Order_Books中本来有50,000条记录,查询后获得30,000条,如果创建新的序表,则内存中的总记录数就是80,000条。事实上,查询出的记录是原序表的一部分,不必创建新的序表,只要用某种数据对象来存储原序表中30,000条记录的引用就够了。这种数据对象就是排列。
排列具有一定的透明性
通常情况下,用户不必刻意区分排列和序表,就像不必刻意区分引用和实体数据。比如前面例子中的查询、排序、交集等算法既可以用于排列也可以用于序表,语法上完全一样:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
=A1.to() |
|
2 |
=A1.select(Amount>=20000 && month(Date)==5) |
=B1.select(Amount>=20000 && month(Date)==5) |
|
3 |
=A1.sort(SalesID,-Date) |
=B1.sort(SalesID,-Date) |
注意:A1中是序表,B1是用其生成的排列。而A2,B2,A3,B3中的计算结果均为排列。
排列之间可以进行集合运算,如2.3.2.2序表是特殊的序列 中的订单计算。而不同序表中的成员总是不同的对象,对序表做集合运算通常没有实际意义,其交集恒定为空。
如果数据结构发生了变化,集算器会自动生成新序表,比如前面的例子中用groups函数计算分组汇总,或者用derive函数在序表中添加字段时。
序表会单向影响排列
不同的序表代表着不同的实体数据,因此修改了某一个序表并不会影响到其他序表。但排列是序表记录的引用,它们具有相同的实体数据,修改了序表会影响排列。如:
|
|
A |
|
1 |
=file("Order_Books.txt").import@t() |
|
2 |
=A1.select(SalesID==363) |
|
3 |
>A1.modify(3, 1:SalesID) |
在工具栏中点击![]() 分步执行,可以看到A1中的序表如下,其中第3条记录的SalesID字段是363:
分步执行,可以看到A1中的序表如下,其中第3条记录的SalesID字段是363:
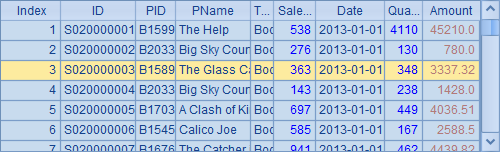
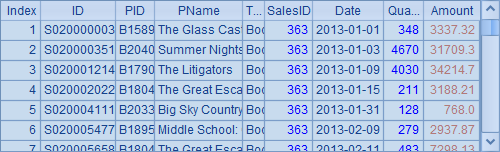
A2从中选出所有SalesID为363的记录,构成排列如下:
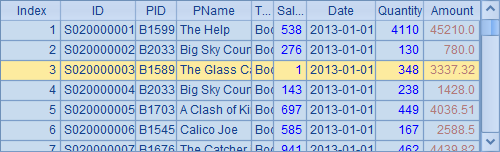
A3中,修改了A1中的序表,修改了其中第3条记录,将其SalesID字段变为1。此时再次查看A1中的序表,可以发现第3条记录已经被修改:
再查看A2中的排列,虽然并没有直接修改A2中的数据,但由于其记录来自序表,因此会发现其中对应的记录也被修改:
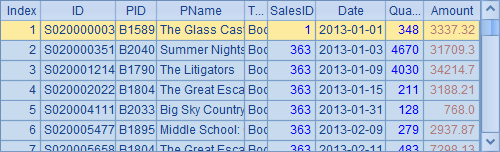
如果有多个排列都源自于同一个序表,则这些排列中的相应数据都会发生变化。
很多时候,这种影响是程序员不希望发生的,比如上面的情况,由于A3中对序表数据的修改,是在A2中执行选出记录之后,因此造成了A2选出的数据中,出现了SalesID不等于363的记录(因为引用未发生变化),这在业务上有时是错误的。
为了避免这种影响,用户应当在生成排列前就完成对序表的修改,比如:
- TSeq.modify(5, 1000: Amount) /将OrderID=5的记录的Amount字段修改为1000,即小于2000。
- RSeq =TSeq.select(Amount>2000) / OrderID=5的记录不会出现在RSeq中。
|
|
A |
|
1 |
=file("Order_Books.txt").import@t() |
|
2 |
>A1.modify(3, 1:SalesID) |
|
3 |
=A1.select(SalesID==363) |
先在A2中修改数据,再执行选出,这样A3中查询出的排列如下:
上述的计算结果才符合业务逻辑。当然,只要理解了序表和排列的引用关系,上述计算顺序是再自然不过的事情了。
需要注意的是,排列不支持modify等修改原序表的函数,所以这种影响是单向和安全,用户可以放心使用排列和序表。