10.2.2用fork语句执行集群计算
在8.1多线程中,我们介绍了fork语句的使用,可以多线程执行一段代码。实际上,上一小节中使用的callx就是在集群中的各个服务器端,执行某个dfx文件中的代码。
所以,callx的计算,也可以用fork来处理,如:
|
|
A |
B |
C |
|
1 |
[192.168.10.229:8281] |
|
|
|
2 |
[124051,128857,131893,136760,139951,145380] |
|
|
|
3 |
fork A2;A1 |
>output@t("calc begin, SID="+string(A3) +". ") |
|
|
4 |
|
=file("D:/files/txt/StockRecord.txt").import@t() |
=B4.select(SID==A3) |
|
5 |
|
=C4.count() |
=C4.max(Closing) |
|
6 |
|
=C4.min(Closing) |
=round(C4.avg(Closing),2) |
|
7 |
|
>output@t("calc finish, SID="+string(A3) +". ") |
return B5,C5,B6,C6 |
|
8 |
=A3.new(A2(#):SID,~(1):Count,~(2):Maximum,~(3):Minimum,~(4):Average) |
|
|
这其实相当于把集群计算中需要重复执行的子网格直接写入了代码块中,可以不必维护多个dfx文件。使用多个分机时,如果需要指定分机,可以在fork函数的最后添加分机执行的工作序号序列s,如fork A2;A1:[[4,5],[1,2,3]]。A3中,收集每个工作返回的结果如下:
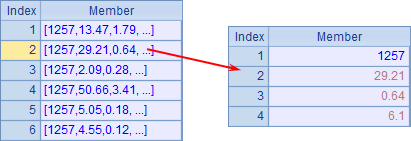
在返回结果序列时,A3中的结果和参数的顺序是一致的,A8将集群结果整理后,得到下表:
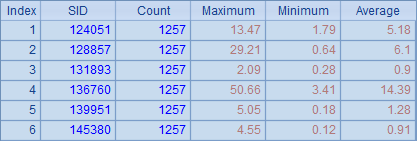
在fork的使用模式里,也可以添加reduce动作,如:
|
|
A |
B |
C |
|
1 |
[192.168.10.229:8281] |
|
|
|
2 |
[124051,128857,131893,136760,139951,145380] |
|
|
|
3 |
fork A2;A1 |
>output@t("calc begin, SID="+string(A3) +". ") |
|
|
4 |
|
=file("D:/files/txt/StockRecord.txt").import@t() |
=B4.select(SID==A3) |
|
5 |
|
=C4.count() |
=C4.max(Closing) |
|
6 |
|
=C4.min(Closing) |
=round(C4.avg(Closing),2) |
|
7 |
|
>output@t("calc finish, SID="+string(A3) +". ") |
return A3,B5,C5,B6,C6 |
|
8 |
reduce |
if(ift(~~),~~.record(~),create(SID, Count, Maximum, Minimum, Average ).record(~~).record(~)) |
|
在reduce代码块中,添加了reduce动作的函数,在第一次reduce动作时,新建结果序表,并将~~中的首个工作结果以及~返回的第二个工作结果数据填入,之后的reduce动作则相应在结果序表中添加记录。执行后,在A3中可以看到执行集群计算的结果:
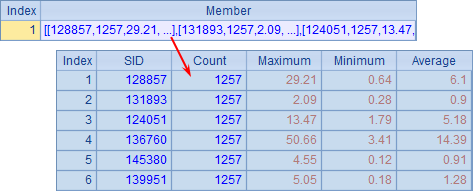
这里只使用了一台分机,其返回的序表即为所需的统计结果。在使用分机的reduce处理结果时,记录的顺序就无法确定了,会由各个工作的完成顺序来决定,因此这里的SID需由各个工作直接返回。