8.2.1并行读取数据
在读取数据表时,如果记录的顺序对计算结果没有影响,则可以用多线程来处理,从而更充分地利用系统资源,以达到提高效率的目的。如果需要使用多线程并行处理,需要在使用函数时添加@m选项,多线程并行读取数据的函数主要是f.import@m()。
读取单个数据文件中的数据时,可以用多线程并行的方法。如:
|
|
A |
B |
|
1 |
=file("PersonnelInfo.txt") |
=now() |
|
2 |
=A1.import@t() |
=now() |
|
3 |
=A1.import@mt() |
=now() |
|
4 |
=string(interval@ms(B1,B2))+"/"+string(interval@ms(B2,B3)) |
|
A2中直接读入数据,A3中添加了@m选项,使用f.import@m(),多线程读取数据。在A4中比较了两种方法的耗时,结果如下:
![]()
使用并行读取数据的方法,也可以获得明显的性能提升。
在多线程读取单数据文件时,系统会将文件拆分为多个部分,分别构成文件游标来分段读取记录。读取数据时,这些文件游标将各自使用独立的线程,类似于上一个例子中多线程读取数据的情况。如果想更详细地了解集算器中如何分段读取数据,请阅读7.8集文件。
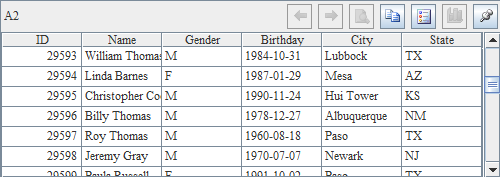
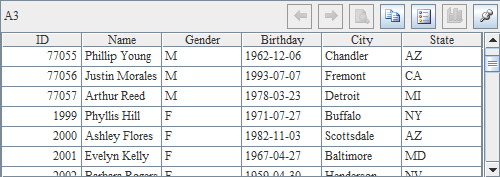
由于并行读取单个数据文件中的数据,同样是使用多个线程同时执行的,因此在结果中记录的顺序也是不定的。可以从下面A2与A3的结果中发现这一点:
在使用f.import@m()时,使用的线程数是由设定的Parallel number of task决定的。这个参数可以在集算器菜单栏中点击Tool>Option,在General页面中设定: