8.1.2使用多线程的性能优势
从执行上看,多线程计算的代码与普通的循环非常类似,那么为什么要用多线程计算呢?下面我们来比较一下多线程与普通循环的区别:
|
|
A |
B |
|
1 |
=file("PersonnelInfo.txt") |
|
|
2 |
=now() |
|
|
3 |
fork to(4) |
=A1.import@t(;A3:4) |
|
4 |
|
return B3.select(City=="San Diego") |
|
5 |
=A3.conj() |
=interval@ms(A2,now()) |
|
6 |
|
|
|
7 |
=now() |
|
|
8 |
for 4 |
=A1.import@t(;A8:4) |
|
9 |
|
>A10=A10|B8.select(City=="San Diego") |
|
10 |
[] |
=interval@ms(A7,now()) |
在这个例子中,从文本文件PersonnelInfo.txt中找到圣地亚哥的员工数据。在2~5行使用多线程,在7~10行使用普通循环。计算时,在B3和B8同样采取分段读取数据的方法。需要注意的是,使用多线程计算时,fork to(4) 不能简写。在A5和A10中,两种方法计算出的结果是相同的:
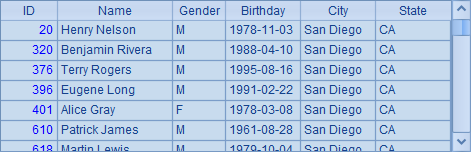
在B5和B10中估算出两种方法的耗时如下:
![]()
![]()
可以发现,由于用多线程计算时,CPU的利用率较高,因此计算耗时会少于使用普通循环。