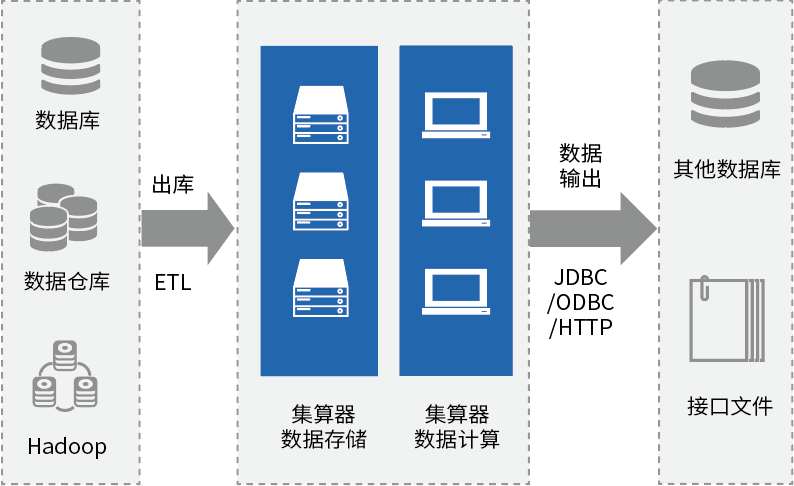
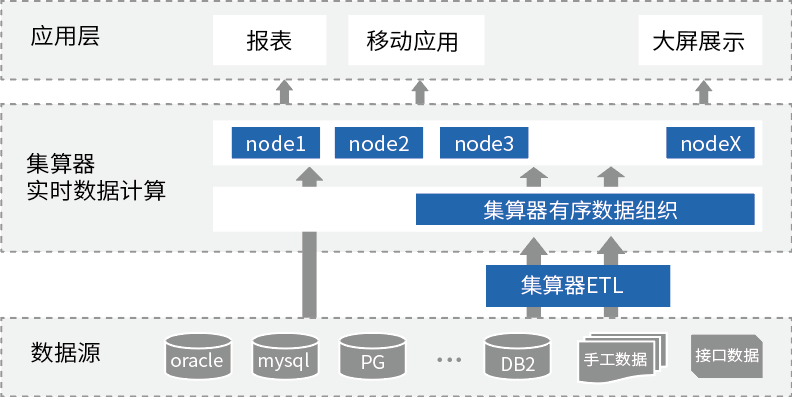
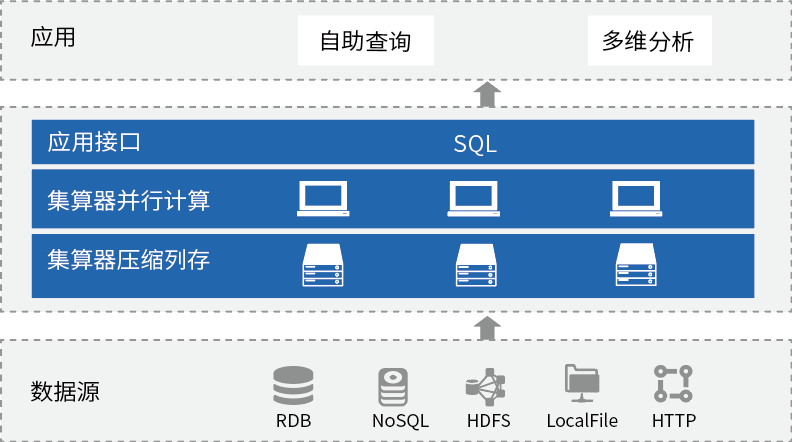
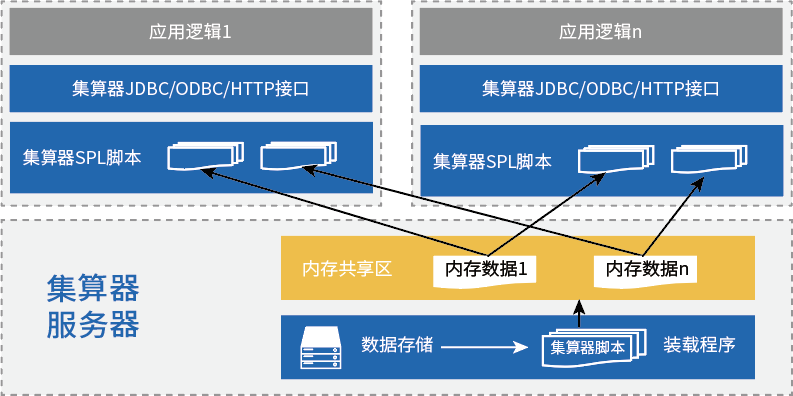
什么才算是同一辆车?车架号相同、车辆vin码相同、车牌号和种类形同。是否贷款车、商业险和交强险等等
一个省的数据几亿条
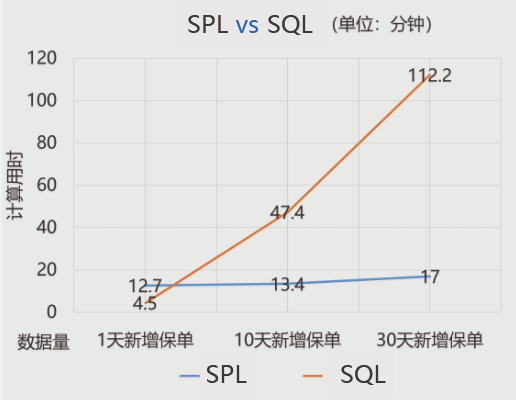
30天新增保单2个小时,90天新增保单长时间跑不出结果
2015年09月到2018年09月
几十万、上百万人访问
使用6台ES服务器基本达到响应要求
代码表改变时要花数小时重新生成数据
【类比】计算1+2+3+…+100=?

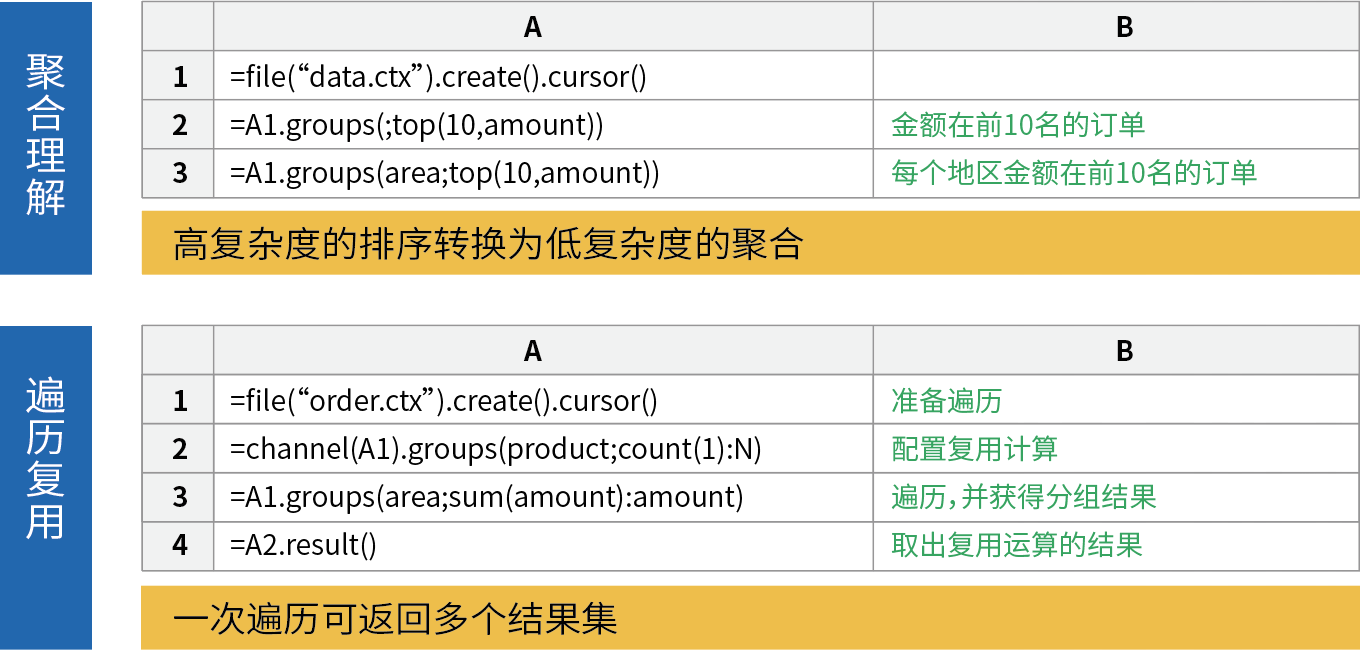
SQL理论上就是大排序后取前10个,效率很低,程序员都知道有不必大排序的办法实现这个运算,却无法用SQL表达,只能用指望数据库引擎自动优化,但复杂情况时数据库并不会优化!
关系数据库的SQL就像只有加法的算术体系,而集算器的SPL则发明了乘法!
集算器还有更多乘法(高性能计算和存储库),人人都能成为高斯(快速实现高性能算法)。

这里许多算法都是集算器的独创发明!
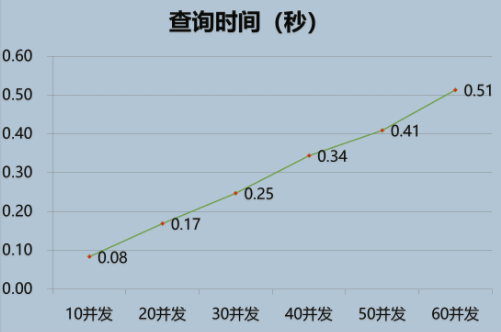
测试结果(时间单位:秒)测试结果(时间单位:秒)
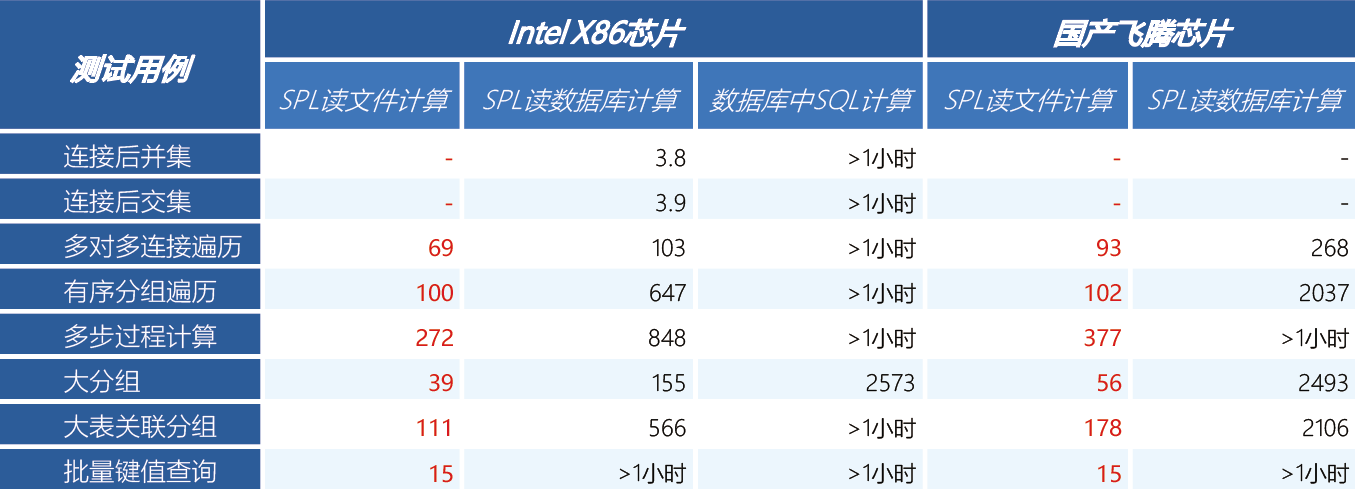
【注】SPL是润乾集算器采用的程序设计语言;SQL是关系数据库采用的程序设计语言
国产飞腾芯片上运行的润乾集算器可以超越Intel芯片上分布式数据库的性能
必须!数据密集型计算的存储是性能保障,传统RDB和HADOOP的低效存储无法实现高性能
集算器针对内存、外存、集群都设计有专用高效数据组织方案,适应于多种运算场景

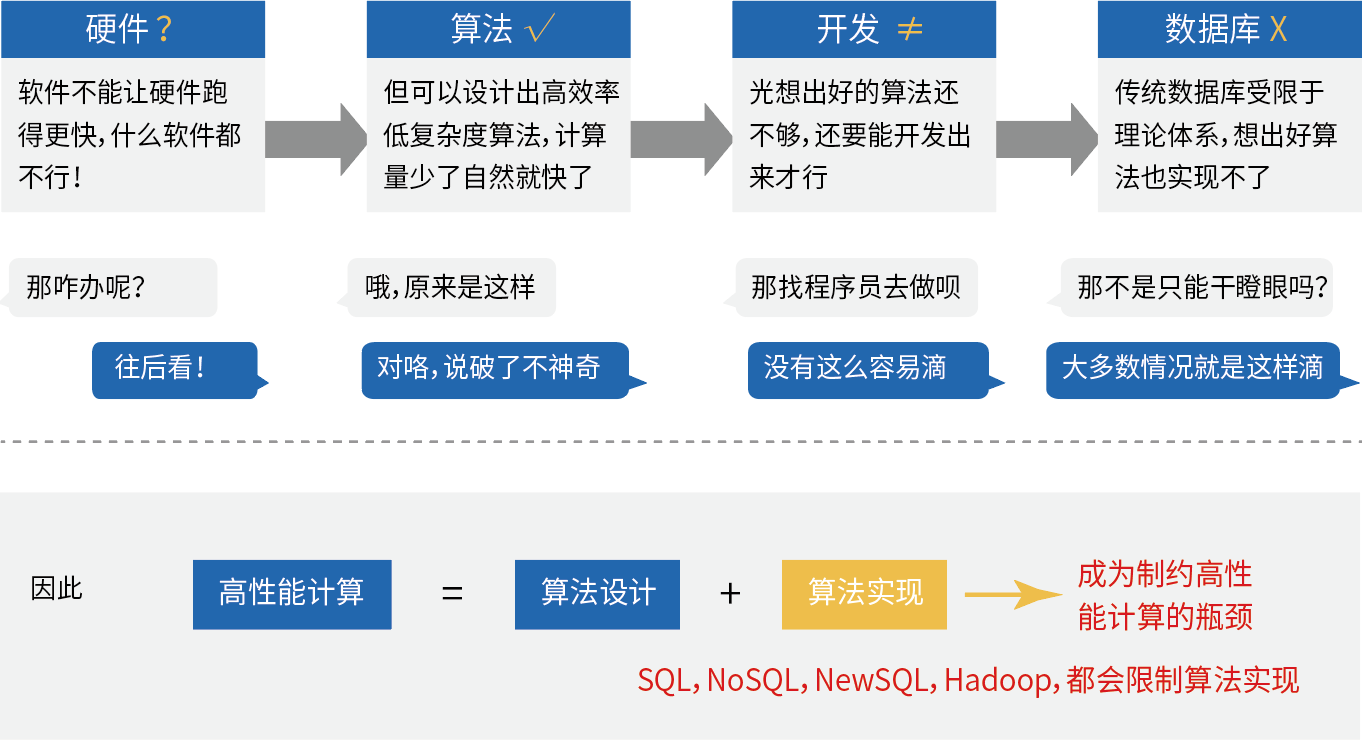
集算器基于全新的计算模型,无开源技术可以引用,从理论到代码全部自主创新
基于创新理论的集算器不能再使用SQL实现高性能,SQL无法描述大部分低复杂度算法
仅对于运算形式规整的多维分析可提供高性能SQL接口,以适应各种前端BI工具
集算器专门用于性能优化,提供了专用的SPL语法
学习SPL不难,数小时即可掌握,数周就能熟练
难的是设计优化算法

所以我们设计了下面的优化流程
最初的1-2个场景,由润乾高级工程师介入配合用户实现
大多数程序员习惯了SQL思维方式,不熟悉高性能算法,需要用一两个场景训练和理解
几十种性能优化套路经历过也就学会了,算法设计和实现并不是那么难

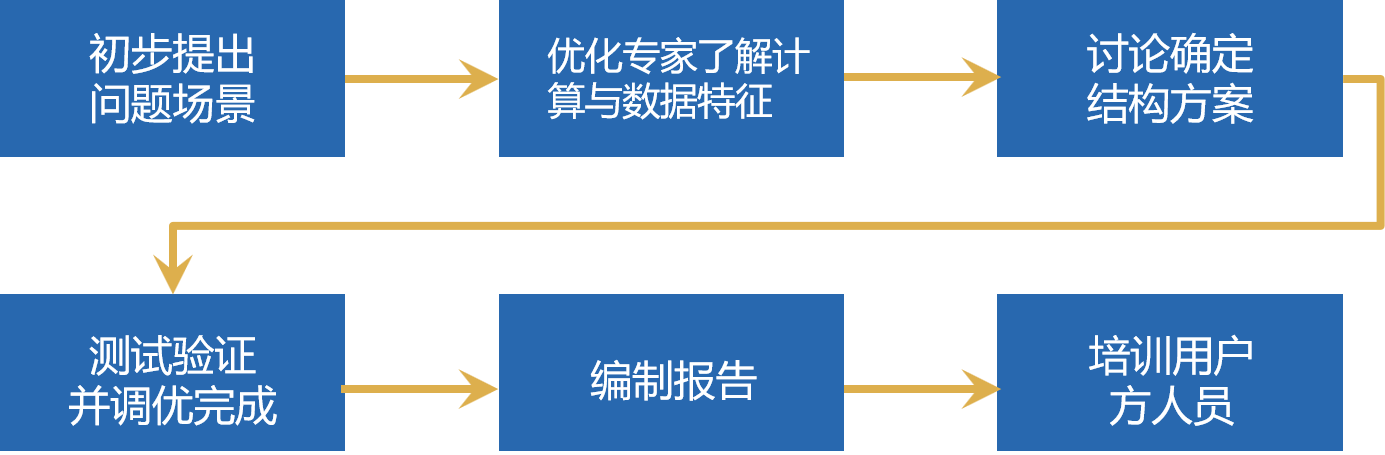
授人以鱼不如授人以渔!