Java程序中的数据计算
由于各种各样原因,我们经常需要在Java程序中进行数据计算处理

系统设计要求,
业务逻辑与数据存储分离
业务逻辑与数据存储分离
数据分散在
不同的数据源中
不同的数据源中

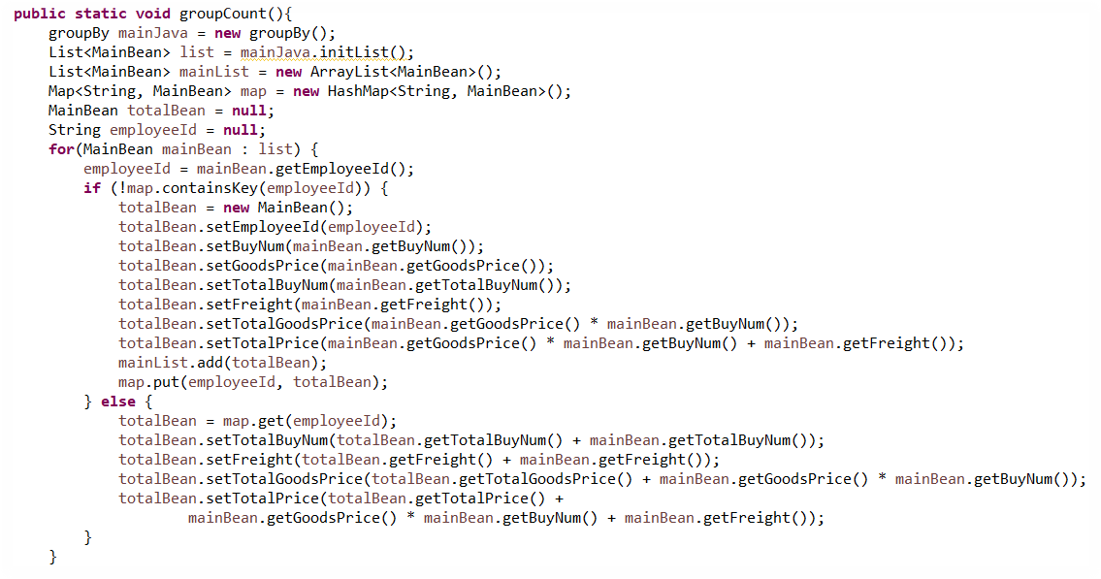
计算逻辑复杂,
SQL实现困难
SQL实现困难

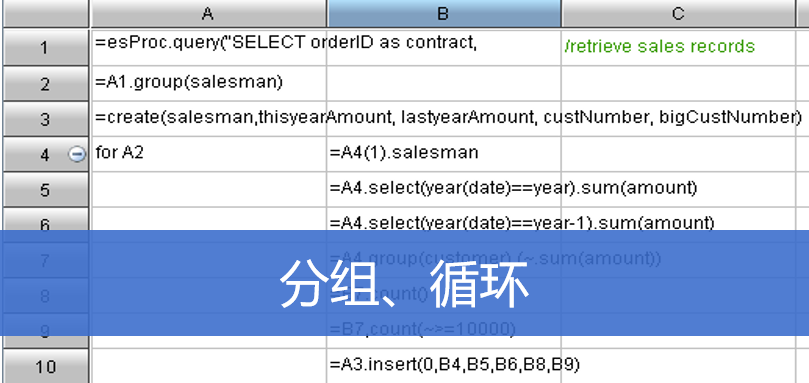
| A | |
|---|---|
| 1 | =file("/Users/test/duty.xlsx").importxls@tx() |
| 2 | =A1.groups(name;count(name):count) |
这类基本运算还可以直接用SQL写:
SELECT name,count(name) FROM user/test/duty.xlsx GROUP BY name
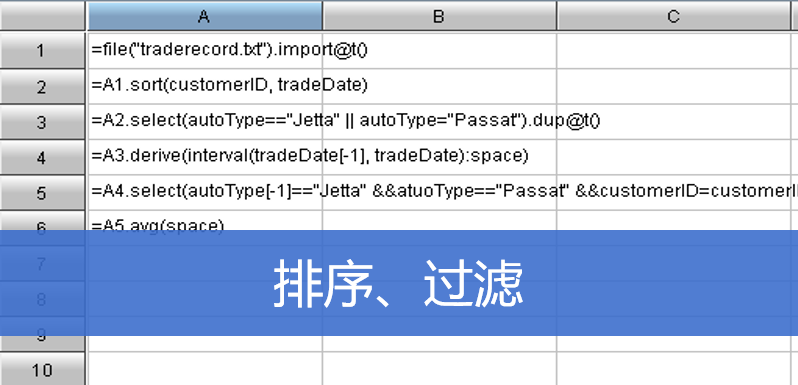
| A | |
|---|---|
| 1 | =file("/Users/test/duty.xlsx").importxls@tx() |
| 2 | =A1.groups(month(workday):mon,name;~.top(3):top3) |
| A | |
|---|---|
| 1 | =connect("mysql") |
| 2 | =A1.query@x("select * from world.countrylanguage where isofficial='T'") |
| 3 | [Chinese,English,French] |
| 4 | =A2.align@a(A3,Language) |
| 5 | =A4.new(A3(#):name,~.len():cnt) |
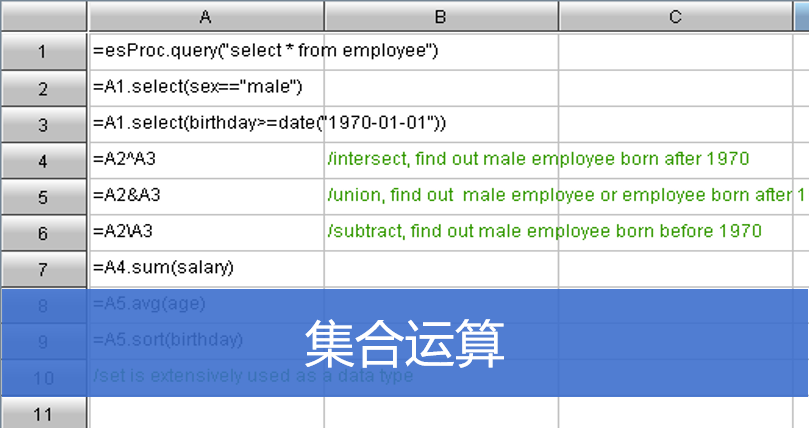
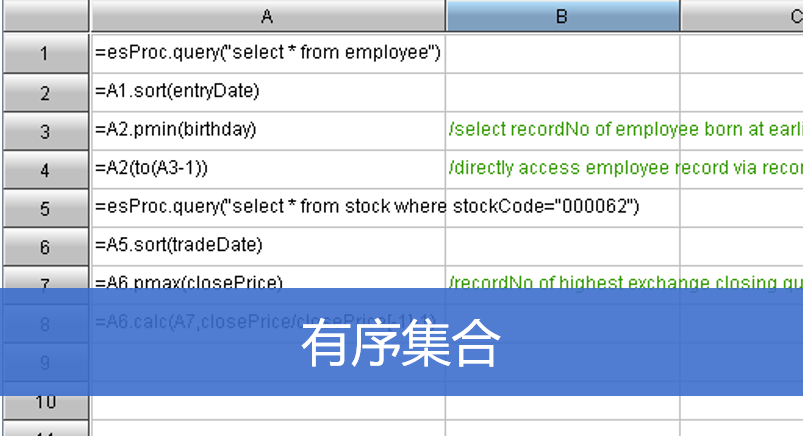
硬编码算法必须和主应用一起编译打包
硬编码算法和主应用存在类依赖,难以隔离,耦合度高
硬编码算法修改后会导致整个应用重新编译部署重启,很难做到热切换
集算器算法无需事先编译
集算器脚本文件与主应用无依赖关系,可外置于JAVA,可单独维护
无需编译无需重启,可热切换

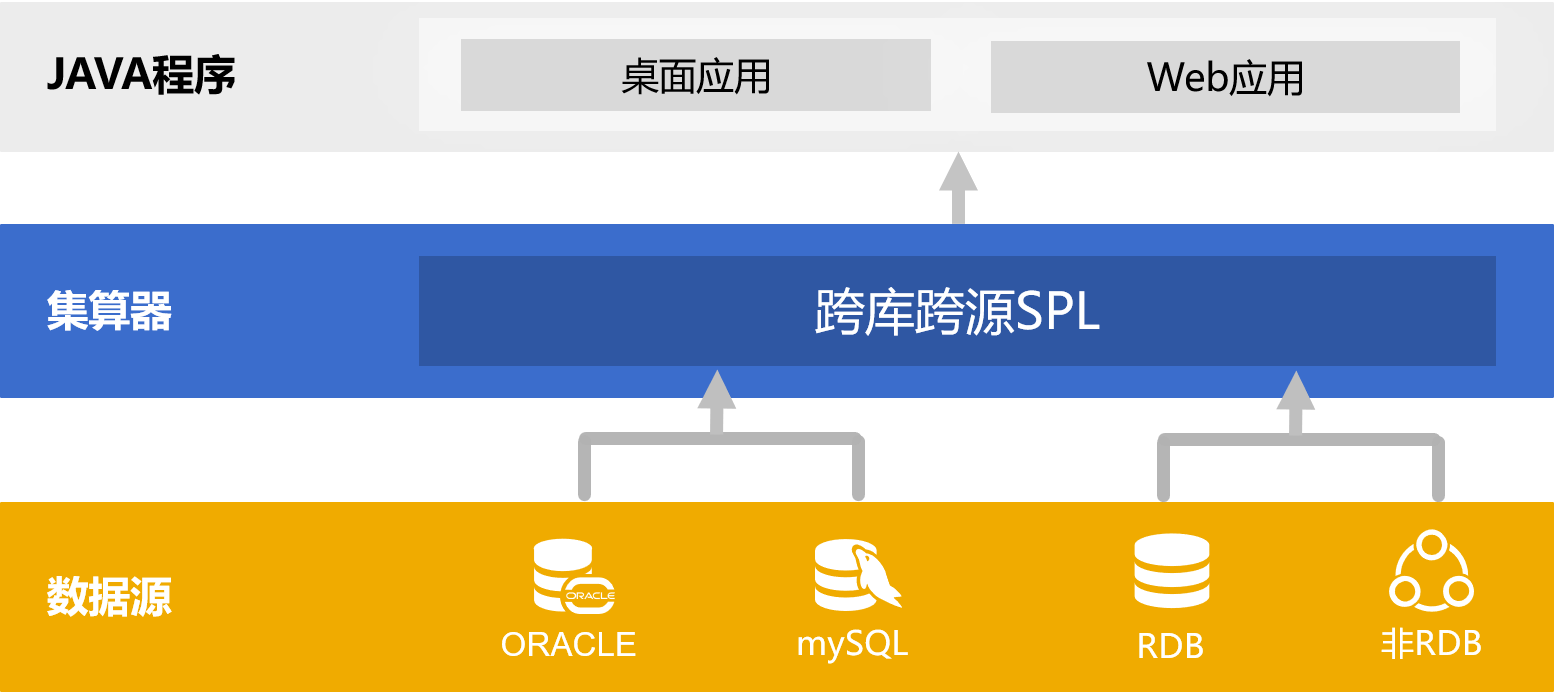
... Connection con = null; Class.forName(com.esproc.jdbc.InternalDriver"); con= DriverManager.getConnection("jdbc:esproc:local://"); //调用存储过程,其中CountName是dfx的文件名 st =(com. esproc.jdbc.InternalCStatement)con.prepareCall("call CountName()"); //执行存储过程 st.execute(); //获取结果集 ResultSet rs = st.getResultSet(); ...