集算器 产品介绍
什么是集算器
集算器是一款专注于(半)结构化数据分析与处理的程序设计语言,面向应用程序员和数据分析员,比SQL、java、perl/python,R语言有更高的开发效率,特别适合业务规则复杂的多步骤运算,可通过简单代码实现多线程并行计算。
集算器不是面向对象的开发语言,没有继承、重载等复杂概念,不适合进行系统底层开发或完整的工具软件开发。
集算器具备敏捷语法、网格风格脚本和完备的调试功能,对结构化/半结构化数据进行了针对性设计,适合进行步骤多、业务规则复杂的商业计算和数据源多样的混合计算。
集算器支持多线程并行计算,性能接近甚至超过传统数据库,可进行大文件大并发的计算任务。
集算器的典型用法包括报表数据源准备、JAVA计算中间层、数据分析与处理、高性能并行计算、桌面级BI工具。
集算器提供了JDBC接口以便集成,也允许通过Command Line直接调用,还可使用独立的IDE进行桌面计算。

集算器的IDE界面:
适用场景
集算器适合以下场景:
- 报表数据源准备:集算器适合报表数据源中业务算法复杂的计算或多数据源跨库计算,并提供标准JDBC接口以无缝集成进报表工具。
- JAVA计算中间件:集算器可作为数据源与JAVA程序之间专门承担计算任务的部件,用以减轻数据库的计算压力,存储压力、并发压力。
- JAVA结构化计算类库:在不方便使用数据库的情况下中,集算器可为JAVA提供结构化计算能力,实现文本计算、大文件计算、多数据源跨库计算。
- 历史数据分析:集算器提供快捷开发,并支持并行计算,适合对数量大的历史数据进行业务复杂的分析任务。
- 定期汇总清算:无需改动数据库,集算器就可以实现总数据量大,并且需要定期汇总清算的任务。
- 数据移植/清洗/整合:集算器适合开发算法复杂、异构数据源或性能要求较高的ETL过程。
- 测试数据生成:集算器可生成种类和特征各异的数据,并且可以批量导出到任意数据库。
- 批量文件处理:集算器的程序性允许它处理格式类似的一批文件。
- 文本日志分析:集算器支持文本文件并行计算,适合有一定复杂性的文本日志分析任务。
- 数据中心服务算法:集算器擅长编写复杂业务逻辑,支持多样性数据计算和并行计算,有很好的集成性易于将算法封装成各种服务协议。
- 即时查询与OLAP后台:集算器允许程序员根据查询特点优化性能,可以加快即时查询和OLAP数据装载的速度。
- 图表绘制:集算器支持底层的图元绘图和高级的统计图展示数据。
集算器的库函数面向宽泛的业务,可用来实现具体的业务算法,但本身不直接提供特定行业、具体业务的算法,不适合以下场景:
- 图像与媒体处理:Walsh变换、傅立叶变换、离散余弦变换、图像旋转。
- 地理信息:瓦片图像存储、最优路径算法。
- 特定的数学算法:回归分析、预测模型、遗传算法。
- 机器学习:决策树、The k-means algorithm、SVM。
产品价值
集算器是纯JAVA产品,具有完备的计算体系和敏捷的语法,支持高性能并行计算。它可以有效提升计算能力,提高开发效率,减轻数据库压力,优化数据管理。
集算器支持多线程并行计算,可以提高大数量的计算性能,并缓解大并发下的计算压力。
集算器支持单数据库的计算,也支持多数据源计算,即多种数据库之间或数据库和非数据库之间的计算。特别地,集算器支持对HDFS的访问,并提供外存计算机制,可进行大文件处理。
集算器支持结构化数据的计算,也支持非结构化计算。它的计算体系灵活而自由,用户可以方便高效地定义自己的个性化算法。
集算器是书写在网格中的数据库计算脚本,它支持格名引用,支持分步计算,可以观察步骤细节,可以将复杂计算目标简化为简单步骤,具备真正的调试功能。
集算器具备敏捷的语法风格,支持集合数据、游离记录、有序集合、对象引用以及集合式分组,它允许用户进行自由的计算,比SQL/SP的开发效率更高。
另外,集算器直接支持输出为JDBC,更容易和JAVA代码、报表工具集成。
集算器具有完备的计算能力,支持高性能内存计算和外存文件的并行计算,因此可以作为计算中间件存在,即数据库和应用程序之间的,专门负责计算的服务,用来解决大数据量、大并发、大吞吐量的难题。因为来自外部的计算压力大大降低,数据库可以更高效的进行数据的安全管理与存储服务。
集算器可以有效分担数据库的计算压力,还可廉价横向扩展,有助于降低数据库软硬件成本。
集算器支持不同数据源之间的计算,并可将计算结果写回多个或单一的数据源,支持关系型数据库,也支持MongoDB、Cassandra等NoSQL数据库。集算器提供了大量函数直接支持结构化数据的计算,同时也支持半结构化数据的计算。集算器可直接访问本地和局域网的文件数据,还可以无缝访问HDFS等冗余系统,它支持通用性较好的Txt/Excel文件,也支持性能较好的私有格式的文件。
集算器脚本不绑定特定的数据源,天生支持多种数据源的混合计算,降低了NoSQL和传统数据库的结合难度。
集算器针对结构化数据优化了算法,支持内存计算、外存计算、并行计算、有序算法,程序员可以根据数据特点和算法特点自由选择优化路径,可以获得比传统数据库和Perl等脚本语言更高的性能。
读取文件时,集算器无需进行数据流的对象转换,读取速度比数据库JDBC明显快。遍历大数据量时,集算器可通过并行处理显著提升性能,而传统数据库提升有限。大数据量并发计算时,集算器可通过并行处理提升性能,比传统数据库性能好,且计算时间更加稳定。实现大文本并行处理,集算器的代码比JAVA和Perl简单,性能比Perl高。内存关联运算时,集算器使用指针定位来完成外键引用,比传统数据库性能更好。进行大数据量脚本运算时,集算器比存储过程性能高数倍。
集算器是专业的数据库计算脚本,具有直观的网格式代码风格,无需定义临时变量,用户通过格名即可引用中间结算结果,从而可以方便地实现分步计算,大的计算目标因此可被分解为多个更容易解决的计算步骤。
集算器支持集合数据、游离记录、有序集合、对象引用、集合式分组,可以自由地访问集合的成员并进行和序号相关的计算;轻松解决商业计算中的各种分组的难题;简化结构化数据的计算,更易于用户从业务角度自然地表达算法,降低业务逻辑到实际代码的转换难度。同样的计算,集算器代码比Java或SQL简短精炼数倍。
集算器是纯JAVA计算工具,直接支持多种数据源并可输出为JDBC,因此可以被报表工具和JAVA语言无缝集成。它的特点是跨平台使用和调用,易于部署和配置,具有良好的开放性,可以支持第三方算法,可以方便地集成到用户现有程序中。
体系结构
集算器分为IDE、JDBC、Command Line、Server四个部分,可跨平台运行在JDK1.6及以上的环境中,可独立使用并且不依赖其他应用服务器或中间件。
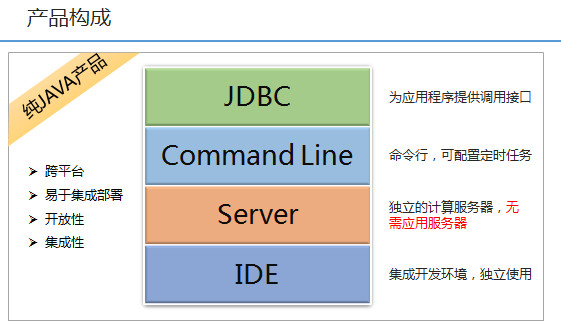
IDE
IDE是桌面应用程序,它是可视化的集成开发环境,可以进行脚本设计、运行、调试等工作,也可以用它来设计图形图表。
它支持网格式代码风格。通过参数和宏,它可以实现任务的批量执行。它支持立即执行模式,设计的同时可以自动执行当前步骤并显示执行结果。
JDBC
JDBC以JAR包的形式存在,它是集算器提供给应用程序的调用接口。
它是标准的JDBC Driver,调用方式和普通数据库的存储过程相同,即JDBC URL\ ResultSet方式。它可以被报表工具和JAVA程序直接集成,作为含有复杂、跨库、高性能计算任务的数据源。
Command Line
Command Line是纯文本的批处理命令文件,通常以cmd\sh结尾。它允许操作系统内置的调度功能来定时执行集算器计算任务,也允许用户在Command Line窗口中手动执行。
通过它,用户可以实现硬编码ETL任务的自动调度,也可以手工启动带参数的数据管理任务。
Server
Server是独立运行的计算服务软件,用于多节点并行计算。节点之间可以协作执行HDFS、数据库、外存文件的读写任务和计算任务。
它可以作为计算中间件减轻数据库的计算压力。通过外存计算,它可以实现数据库的优化管理。
集算器 Server至少应配置千兆网卡。