【数据蒋堂】第9期:报表应用的三层结构

在传统的报表应用结构中,报表工具一般都是与数据源直接连接,并没有一个中间的数据计算层。确实,大部分情况下的报表开发并不需要这一层,相关的数据计算在数据源和呈现环节分别处理就够了。不过,在开发过程中,我们发现,有一部分报表的计算即不适合在数据源也不适合在呈现环节实现,这类报表在数量上并不占多数,但耗用的开发工作量占比却很大。
有过程的计算
报表工具都可以完成计算列、分组排序等运算,有些报表工具还提供了跨行组运算和相对格与集合的引用方案,可以完成颇为复杂的运算。
不过,报表工具中的运算是一种状态式的计算,也就是把所有计算表达式写在报表布局中,根据依赖关系自动处理计算次序。这种方法很直观,在依赖关系不太复杂时能一目了然地了解各单元格的运算目标。但是,在依赖关系较为复杂,数据准备计算需要分成多步时,状态式计算就困难了。如果一定要在报表中实施过程式计算,常常需要借用隐藏格,而隐藏格不仅将破坏状态式运算的直观性,还会占用更多不必要的内存。
比如要列出销售额占前一半的大客户,如果不借助数据准备环节,就要在报表中使用隐藏行列手段将不该列出来的条目隐藏,而不能直接过滤掉。再比如带明细的分组报表要按汇总值排序,需要先分组后排序,许多报表工具无法控制这个次序。
还有个典型例子是舍位平衡,明细值四舍五入后再合计,可能会与合计值的四舍五入值不相等,会造成了报表上明细与合计数值不一致,需要根据合计的舍入值倒推明细的舍入值,这种计算的逻辑并不复杂,但即便用了隐藏格也难以由报表工具完成。
多样性数据源
与多年前的单一数据源不同,现在有许多报表的数据源并不只来源于关系数据库,还可能是NoSQL数据库、本地文件、从WEB上传来的数据等。这些非关系数据库的数据源缺乏标准的数据获取接口和语法,有些甚至没有最基本的过滤能力。而计算报表时总还要进行一些过滤甚至关联运算,虽然报表工具一般都能提供这些计算能力,但由于都是内存计算,只适合于数据量较小的情况,数据量较大时就会导致容量负担过重。而且,大多数报表工具也不能很好地处理象json或XML这种多层数据,也没有灵活编码能力以登录远程WEB服务获取数据。
动态数据源也是常见的需求,报表工具使用的数据源一般事先配置好的,不能根据参数动态选择,直接使用报表工具无法实现。报表被用于通用查询时,取数用的SQL不能简单地用参数控制条件,而经常可能要替换某个子句,有些报表工具支持宏替换,能够一定程度地解决这个问题,但根据参数计算宏值也是个有条件和过程的运算,直接在报表工具中很难完成。
性能优化问题
我们在往期的文章中曾谈到过,大多数情况的报表性能问题都需要在数据准备阶段来解决,其中有许多场景都不能在数据源内部处理。比如并行取数本来就是解决数据源IO性能问题,只能在数据源外部实现;可控缓存需要在外存写入缓存信息,也不能在数据源内部处理;清单列表中的异步数据缓存和按页取数的功能,都不是数据源本身提供的能力;即使可以在数据源环节处理的多数据集关联问题,在多数据库或非数据的场景、以及希望减轻数据库负担时,仍然需要在数据源外部解决。这些无法在数据源内部处理的场景,显然也无法在报表环节处理。
数据计算层
如果把传统报表应用结构的两层改成三层,增加一个中间的数据计算层,这些问题就容易解决了。
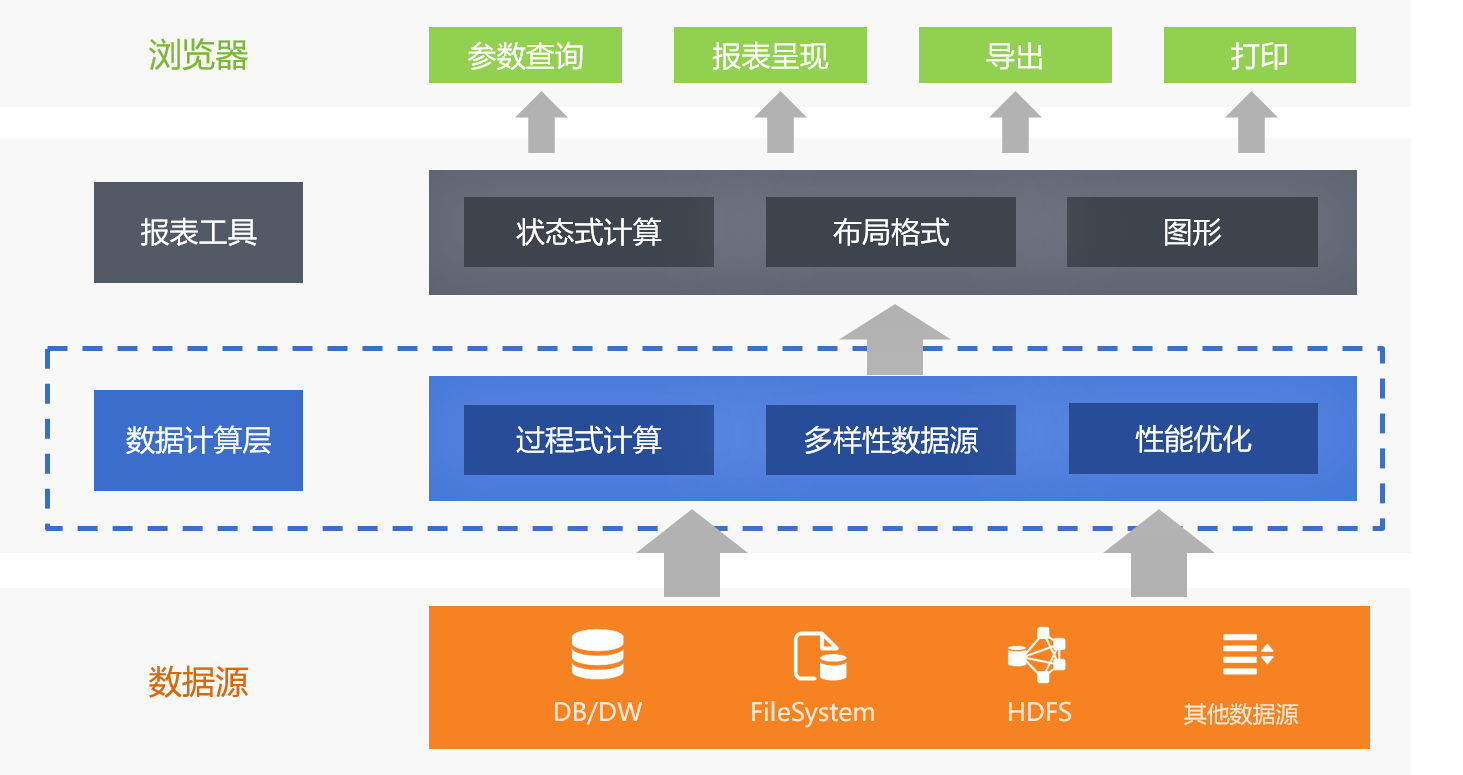
上述的各种运算都可以在数据计算层实现,报表工具只解决呈现问题以及少量适合状态式的直观计算即可。
其实,传统报表应用结构虽然没有刻意强调数据计算层,但仍然有这一层,只是比较隐蔽。典型的实现手段就是使用数据源中的存储过程或者在应用中使用报表工具的自定义数据源接口。存储过程能够解决一些过程式计算和性能优化问题,但它只能应用于单个数据库中,相当于在数据源内部的处理,对于必须在数据源外处理的场景无能为力,有较大的局限性。自定义数据源则在理论上可以解决上述所有问题,而且几乎所有报表工具都提供有这个接口,所以这种方式的应用更为广泛。
那么,使用报表工具的自定义数据源是否就可以方便地实现数据计算层呢?我们将在下一期讨论。