趣味集算:wordcount

WordCount差不多是最常用的分布式系统练习程序了,Hadoop就经常用这个当例子。我们来看用集算器怎么做wordcount。
先从单线程开始。
例如,D:\files\novel目录中,有一些小说文档,现在,需要统计这些小说中哪些单词最为常用:
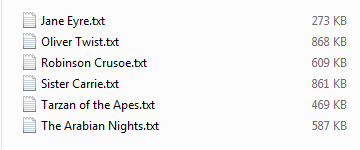
在集算器中,如果不嫌写得长,只要一句代码就可以搞定了:
| A | |
| 1 | =directory@p("D:/files/novel").(file(~).read().words().groups(lower(~):Word;count(~):Count)).merge(Word).groups@o(Word;sum(Count):Count).sort@z(Count) |
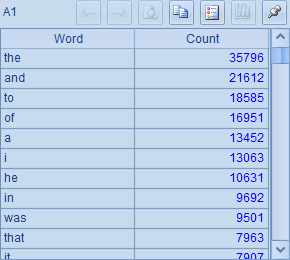
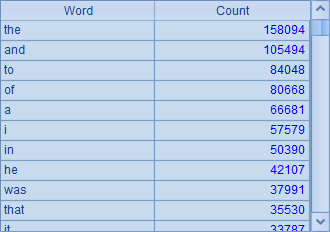
怎么样,是不是超级简单?计算后,A1中得到的结果如下:
不过,这句确实有点长,为了便于理解,我们可以把它拆成多步来执行:
| A | B | C | |
| 1 | =directory@p("D:/files/novel") | [] | =now() |
| 2 | for A1 | =file(A2).read().words() | |
| 3 | =B2.groups(lower(~):Word;count(~):Count) | ||
| 4 | >B1=B1|[B3] | ||
| 5 | =B1.merge(Word) | =A5.groups@o(Word;sum(Count):Count).sort@z(Count) | =interval@ms(C1,now()) |
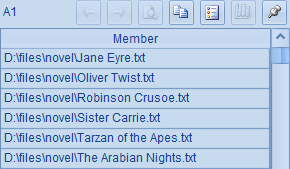
在A1中,列出目录中的各个文件:
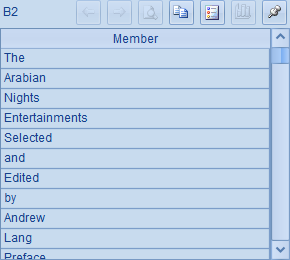
第2~4行循环统计每个文件中的单词。B2中读取文件中的文本并拆分成单词:
B3中统计出当前文档中每个单词出现的次数,统计时将单词转换为小写字母,以避免大小写变化的影响。结果将按照单词的字典顺序排列:
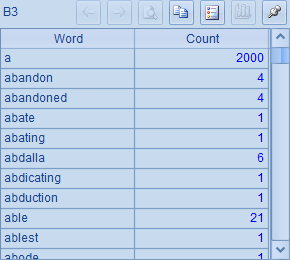
在每个文档统计完成后,在B4中将结果记录到B1中,所有文档统计后,B1中结果如下:
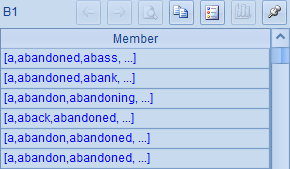
在A5中,将这些结果按照每个单词归并起来,结果如下:
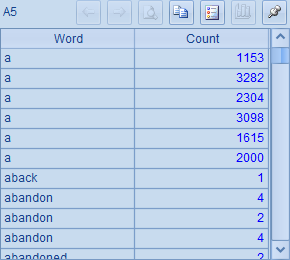
B5中,将归并后的统计结果按每个单词聚合计算,再将结果按Count降序排列,可以得到和前面单条语句时相同的结果:
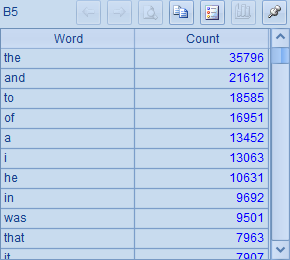
在C1和C5中,通过记录执行开始前后的时刻,估算出计算所需的毫秒数如下:
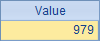
可见,执行效率还是非常高的。
搞完单线程,我们再来试试多线程的搞法。
并行计算会不会麻烦很多啊?看看代码吧:
| A | B | C | |
| 1 | =directory@p("D:/files/novel") | =now() | |
| 2 | fork A1 | =file(A2).read().words() | |
| 3 | =B2.groups(lower(~):Word;count(~):Count) | ||
| 4 | =A2.merge(Word) | =A4.groups@o(Word;sum(Count):Count).sort@z(Count) | =interval@ms(C1,now()) |
嗯,好象差不多嘛,就是把A2的那个for换成了fork,其它代码基本没什么变化。看看C4中的计时情况
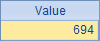
果然快了,并行真地起了作用(俺的笔记本只有双核,有这个性能提高也就差不多了)。
这个fork语句就会自动把本来单线程串行执行的for循环变成多线程并行循环计算,程序员完全不用操心线程管理的事,是不是很简单?
搞完多线程,现来搞集群。
懒得真搞多个服务器来,就用一台机器启动多个进程模拟一下吧。在集算器安装目录的esProc\bin路径下,可以找到esprocs.exe文件,可以直接运行它来启动或配置服务器:
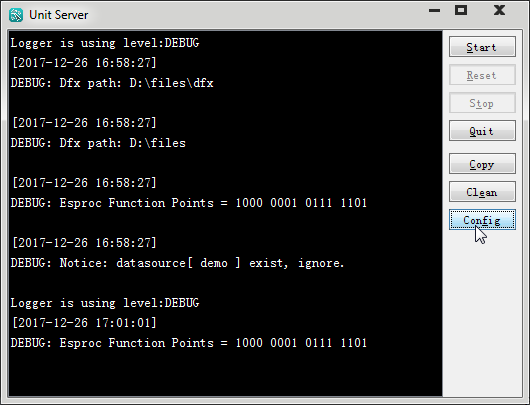
在首次用Start按键启动服务器之前,可以先点击Config配置并行服务器的相关信息,如在Unit页面中配置本机中所要启动的服务器ip及端口:
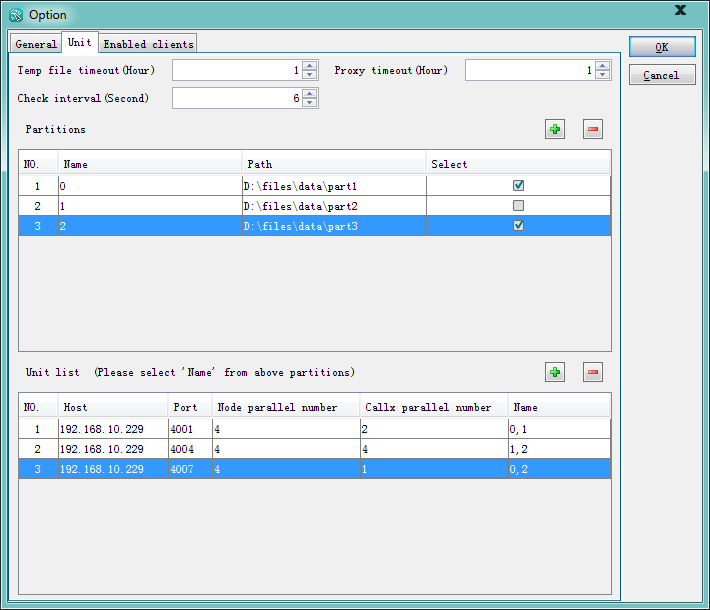
配置完成后,就可以回到服务器主窗口启动服务器。重复执行esprocs.exe可以再启动两个服务器,这3个服务器将依次使用配置中设置的ip和端口。这样单机上的服务器集群就准备完毕了。
下面准备统计4个路径中所有文档的单词,由于这里使用单机模拟服务器集群的,所以每个服务器都是共用相同路径的,如果是远程服务器,设定时路径可能也会有所差异。
| A | B | C | |
| 1 | [192.168.10.229:4001,192.168.10.229:4004,192.168.10.229:4007] | [D:/files/novel1,D:/files/novel2, D:/files/novel3,D:/files/novel4] | |
| 2 | fork B1;A1 | =directory@p(A2) | |
| 3 | fork B2 | =file(B3).read().words() | |
| 4 | =C3.groups(lower(~):Word;count(~):Count) | ||
| 5 | return B3.merge(Word) | ||
| 6 | =A2.merge(Word) | =A6.groups@o(Word;sum(Count):Count).sort@z(Count) |
在计算时,用4个文件路径作为参数,需要执行4个子任务分别计算某个路径中文件的单词数。只需要在fork后面加上各个服务器节点的地址,这些子任务就可以由集算器自动分派给服务器节点去计算并将结果汇总,程序员根本不用操心这些小问题。最后在B6中计算出结果如下:
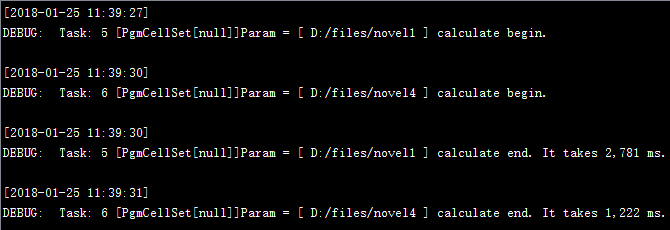
从各个服务器窗口中,可以看到集群计算任务的分配执行情况:


怎么样?很简单吧,Hadoop还没搭建起来的时间,咱已经把活干完了。